Techniques
Vous trouvez une masse d'informations sur ce que je connais ou ce que j'ai découvert...
Souvent il s'agit plus d'un pense-bête que d'une page "tutorial"
Debian
Ce que ce mot peut faire peur au gens: "DEBIAN"... j'ai découvert le monde unix il y a plus de 15 ans, quand j'étais étudiant avec SLACKWARE... et depuis je regrette parfois de ne pas avoir le temps... depuis quelques mois, je me plonge plus fort dans DEBIAN... et le pire, c'est que jamais je ne suis déçu...
Gerer une DEBIAN, c'est moins facile qu'un Windows, mais c'est tellement plus gratifiant; on se sent comme faisant partie d'une élite... bon c'est aussi avoir de la patience car c'est 80% du temps sur internet pour trouver les réponses, 15% à poser à GOO*LE les bonnes questions, et 5% du temps à les appliquer...
mais c'est tellement Funky comme OS... qu'on lui pardonne d'être "Libre" :D
Debian - Mise à jour 6 -> 7 -> 8
J'ai décidé de mettre a jour mon serveur... de la version squeeze vers la version wheezy... et ensuite jessie
Cela semble facile à première vue, mais comme je préfère me méfier, j'ai fait un labo avec un "clone" de mon serveur, et tenter sur ce clone de mettre au point LA procédure...
Lors de ma première tentative, le serveur (de test) n'a JAMAIS redémarrer, ce qui me fait dire que ce n'est pas si facile... j'ai donc compilé ici mes remarques et mes notes sur ma mise à jour (et mes galères aussi).
Préparation de la plateforme
DSpam et amavis
Premier essai, l'upgrade plante à cause de dspam et de amavisd-new (J'ai fait mon malin et installé depuis les sources de sourceforge), après de looonnngues heures de recherche sur comment supprimer un paquet qui a été installer à la main (mais pas bien) et que debian a ensuite pris (mal) sous son aile....
Voilà ce qu'il convient de faire:
vu les soucis avec dspam et amavisd, on stop les service et SURTOUT on le retire du init.d...,
Mais cela ne suffit pas, il faut aussi PURGER les dpkg et les apt cache, je pense que le insserv -r n'est pas nécéssaire (car fait par le purge) mais ca fait toujours bien de le faire...
dpkg -r dspam
dpkg -P dspam
mv /var/lib/dpkg/info/dspam* /tmp/
dpkg --remove --force-remove-reinstreq dspam
dpkg --purge --force-remove-reinstreq dspam
insserv -r /etc/init.d/dspam
dpkg -r amavisd-new
dpkg -P amavisd-new
mv /var/lib/dpkg/info/amavis* /tmp/
dpkg --remove --force-remove-reinstreq amavisd-new
dpkg --purge --force-remove-reinstreq amavisd-new
insserv -r /etc/init.d/amavis
Clean-up de dspam et amavis
Je ne sais pas si c'est encore nécéssaire... mais dans le doute, on le fait:
rm -r /var/spool/dspam/data/
rm /etc/init.d/dspam
Ca m'apprendra a ne pas suivre les paquets de la distribution et a vouloir faire le malin...
Apache
Certains mod d'apache semble ne pas exister dans debian 7, ou du moins il ne passe pas: mod_dav_svn.so, on le désactive directe:
Changement de version
Il suffit de remplacement "squeeze" par "wheezy" ou "jessie" dans le(s) fichier(s) suivant(s) :
Et de remplacer "6" par "7":
Oui, j'utilise aussi owncloud sur ce serveur...
Mise à jour
Et on lance le bouzin:
apt-get dist-upgrade
J'ai choisis de conserver les paramêtres IPv4 et IPV6, MySQL et après un peu de travail (du serveur) premières questions, j'ai choisis là d'importer les nouveaux fichiers de base, il me faudra controler TOUT les paramètres de ces derniers:
Re-installer le fichier awstats qui serait manquant dans le /etc/cron.d/
fail2ban.conf:
jail.conf: là c'est surtout la durée de bantime qui est racourcie
/etc/roundcube/main.inc.php: pas fou
Par contre, j'ai choisis de conserver MES paramêtres pour:
/etc/phpmyadmin/apache.conf: j'avais juste pas envie de refaire ma config...
/etc/roundcube/debian-db.php: pas fou
Configuration particulière
linux-base : update device IDs : YES
amavisd-new: plus de fichier monolitique, ca tombe bien, j'avais quelques soucis avec amavisd-new...
Un petit reboot et hop... c'est fait (sauf que le kernel est toujours un 2.6, mais pas pour longtemps)
Mise a jour du kernel
Là aussi rien de très compliqué... on check la version (surtout le type de kernel):
Linux version 2.6.32-5-amd64 (Debian 2.6.32-48squeeze3) (dannf@debian.org) (gcc version 4.3.5 (Debian 4.3.5-4) ) #1 SMP Fri May 10 08:43:19 UTC 2013
Dans mon cas, il s'agit d'une amd64, donc je selectionne la dernière image amd64:
apt-get install linux-image-amd64
Et hop, c'est fait... (ne pas oublier de rebooter pour tester), ensuite vous pouvez supprimer l'image 2.6 (ou pas, c'est votre choix):
rm /boot/System.map-2.6*
rm /boot/config-2.6*
rm /boot/vmlinuz-2.6*
Puis une petite mise à jour de grub:
Et on reboot pour controler, si vous vous planter là, ça ne démarrera plus.
N'oubliez pas de mettre votre debian a jour pour le nouveau kernel...
apt-get upgrade
C'est idiot, mais j'avais oublié, du coup plein de truc ne fonctionnaient plus...
Suivit en cas de virtualisation
Si vous êtes en virtual, n'oubliez pas de refaire l'installe des VMWareTools.
Remise des parametres au "carré"
Apticron
/etc/apticron/apticron.conf
fail2ban
/etc/fail2ban/jail.conf
maxretry = 2
maxretry = 2
Etc..
Roundcube
/etc/roundcube/main.inc.php
$rcmail_config['username_domain'] = 'votre-domaine.tld';
[UPDATE]
Roundcube n'est plus maintenu... pour avoir la dernière version, il faut le faire "a la main'...
Amavisd-new
Voir la page dédiée...
Apache2
en passant a jessie, on "reçoit" aussi apache 2.4... c'est cool sauf que:
la config n'est plus la même:
pour chaque site, il faut revoir la configuration des accès:
en configuration 2.2 vous aviez
Deny from all
en configuration 2.2 vous aviez
Allow from all
en configuration 2.4 cela devient:
Debian Join Domain
Souvent, quand on a un environnement windows, on dispose aussi d'une solide base utilisateurs... quand on déploit des serveurs Debian... ben ils sont souvent authetifier "en local"... ce qui peut devenir insuportable quand vous avez beaucoup d'utilisateurs a synchronisé entre votre base debian "local" et vos domaines Controllers...
Heureusement, Linux n'est pas raciste et peut authentifier vos utilisateurs via vos domain controllers...
DNS et réseaux
Je pars du principe que votre serveur est installer avec les dns et une IP fixe... sinon
Sur votre serveur DNS windows, ajoutez un 'A Record' ayant le même nom de serveur (ex: debian) et son IP.
N'oubliez pas de vérifier votre résolution réseaux
un petit ping vers vos DC sera aussi un bon moyen de controler votre configuration et la bonne résolution des dns externes.
Vérifiez aussi le réverse dns, vous pourriez avoir des surprises...
dig -x 192.168.0.26
N'allez surtout pas plus loin si vous avez le moindre problème...
Synchroniser le temps
Il vaut mieux que tout vos serveurs soit à la même heure... Dans la pratique, c'est même un règles élémentaires pour domaine.
Comme Kerberos est un protocol sécurisé sur une base de ticket,le temps (heure) risque de vous poser pas mal de problème de synchro voir de vous refuser l'autentification si vos serveurs ne sont pas à la même heure...
Modifiez le fichier en pécisant le nom complet de votre(vos) time server(s)... Et relancez le service ntpd, puis testez vos serveurs
ntpq -p
Vous devriez avoir vos serveurs avec des informations (sinon vous avez un probleme de dns ou de serveur cible).
Kerberos
Là, nous entrons dans le vif du sujet...
Installation
Si d'aventures, debconf devait vous demandez des informations, acceptez les informations par défaut, nous alons quand même tout vérifier "à la main"...
Configuration
Par sécurité, nous faisons quand même une copie des fichiers de base:
nano /etc/krb5.conf
Nous stoppons maintenant les services que nous allons modifier:
service krb5-kdc stop
Nous allons maintenant configurer notre domaine dans le krb5.conf:
default_realm = EXAMPLE.LOCAL
dns_lookup_kdc = no
dns_lookup_realm = no
ticket_lifetime = 24h
; for Windows 2003
default_tgs_enctypes = rc4-hmac des-cbc-crc des-cbc-md5
default_tkt_enctypes = rc4-hmac des-cbc-crc des-cbc-md5
permitted_enctypes = rc4-hmac des-cbc-crc des-cbc-md5
; for Windows 2008 with AES
; default_tgs_enctypes = aes256-cts-hmac-sha1-96 rc4-hmac des-cbc-crc des-cbc-md5
; default_tkt_enctypes = aes256-cts-hmac-sha1-96 rc4-hmac des-cbc-crc des-cbc-md5
; permitted_enctypes = aes256-cts-hmac-sha1-96 rc4-hmac des-cbc-crc des-cbc-md5
# The following libdefaults parameters are only for Heimdal Kerberos.
v4_instance_resolve = false
v4_name_convert = {
host = {
rcmd = host
ftp = ftp
}
plain = {
something = something-else
}
}
fcc-mit-ticketflags = true
dns_lookup_realm = false
dns_lookup_kdc = false
[realms]
EXAMPLE.LOCAL = {
kdc = domaincontroller1.example.local
kdc = server2.example.local
admin_server = domaincontroller1.example.local
default_domain = example.local
}
[domain_realm]
.example.local = EXAMPLE.LOCAL
example.local = EXAMPLE.LOCAL
[login]
krb4_convert = true
krb4_get_tickets = false
Tout ce qui est en rouge est à changer... par vos valeurs....
Login ou logs ?
après cette opération, vous devriez vous loguer avec vos données 'domaine'...
Si vous désirez logguer kerberos (pourquoi pas en fait...) ajoutez cette section:
kdc = FILE:/var/log/kerberos/krb5kdc.log
admin_server = FILE:/var/log/kerberos/kadmin.log
default = FILE:/var/log/kerberos/krb5lib.log
N'oubliez surtout pas de créer le dossier 'kerberos' dans votre '/var/log'
Dans ce cas, pensez aussi a créer une entrée 'logrotate' pour vos kerberos log... Sinon, votre log risque de devenir indigeste rapidement:
Voici le contenu de ce fichier (pour un archivage par jour et une conservation de 7 jours):
daily
missingok
rotate 7
compress
delaycompress
notifempty
}
Redémarrage de Kerberos
Le plus simple dans ce cas sera un reboot... (surtout avec toutes les configs qui ont changer) mais en théorie ce n'est pas nécéssaire...
Configurer winbind
Winbind est le service qui se chargera de faire la transition entre le local et votre domain Active Directory (via kerberos)
[global]
workgroup = EXAMPLEDOM
realm = EXAMPLE.LOCAL
server string = %h server (Samba %v)
load printers = no
security = ads
local master = no
domain master = no
preferred master = no
wins server = 192.168.11.100
dns proxy = no
winbind uid = 10000-20000
winbind gid = 10000-20000
winbind use default domain = yes
interfaces = eth0 lo
syslog = 0
log file = /var/log/samba/log.%m
max log size = 1000
panic action = /usr/share/samba/panic-action %d
invalid users = root
template homedir = /home/%D/%U
template shell = /bin/bash
winbind offline logon = yes
winbind refresh tickets = yes
Relancer les services
Votre configuration complete; il suffit de relancer les services:
service winbind restart
Configurer nsswitch
Cet outil est utilisé par le système pour faire la recherche des utilisateurs et des groupes dans l'Active Directory, de base l'outil est bien plus que cela, mais nous nous contenterons de ce type d'informations pour commencer...
ajouter "winbind" aux bons endroits:
#
# Example configuration of GNU Name Service Switch functionality.
# If you have the `glibc-doc' and `info' packages installed, try:
# `info libc "Name Service Switch"' for information about this file.
passwd: files winbind
group: files winbind
shadow: files winbind
hosts: files dns wins
networks: files
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: nis
Gerer le mapping via PAM
PAM : Pluggable Authentication Module
Ce module permet de changer les informations de authentification... Les fichiers de configuration se trouvent dans /etc/pam.d/
# nano /etc/pam.d/common-account
account required pam_unix.so
# nano /etc/pam.d/common-auth
auth required pam_unix.so use_first_pass
# nano /etc/pam.d/common-session
session sufficient pam_winbind.so
session required pam_unix.so
Joindre le domaine
il vaut toujour mieux acquerir un ticket kerberos, utiliser un compte domain admin comme user_admin, vous devrez aussi fournir le mot de passe de ce compte...
Bien entendu vérifiez votre ticket...
Si tout est en ordre, enfin la commande ultime...
Joined 'server_name' to realm 'example.local'
Debian et sécurité
Petite mise en garde si dans vos dépots débian, vous avez une référence a un dépot "debian-multimedia.org", il est urgent de la supprimé, en effet le domaine a été racheter par un zozo en ukraine...
cette affaire nous rappel de bien gérer les clés de cryptographie des dépots...
plus d'infos sur le site linuxfr.org
bref, vérifiez vos /etc/apt/sources.list et /etc/apt/sources.d au cas où vous utilisez ce dépot non officiel...
Debian in Domain - Commandes sympa...
Voici quelques commandes que l'on peut utiliser après intégration d'un domaine :
- liste des users du domaine : wbinfo -u
- liste des groups du domaine : wbinfo -g
- vérifier qu'un utilisateur particulier est correctement reconnu :wbinfo -a MonDomaine\bilbeau%LeMotDePasse
Installer Debian 6 avec une IP Fixe
Si vous installez souvent des Débians via network (et que vous avez un solide firewall), il vous faut installer débian avec une IP fixe... c'est simple sur le papier... un peu moins en réalité... quoi que...
dans le menu graphique... Choissisez 'Install'... et ne faites pas [ENTER] mais [TAB]...
Et là, ajoutez en fin de ligne (juste après le '... quiet') la commande (attention vous êtes en querty):
Vous pouvez valider la commande complete avec [ENTER]; le wizard d'installation normal se lancera... mais vous demandera les parametres pour le réseau (ip, masque, gateway, dns ,etc..).
Installer OTRS sous DEBIAN...
pour des raisons de test, j'ai du installer un OTRS sous DEBIAN... je me suis inspiré du tutorial fournis sur le wiki d'OTRS, mais celui-ci concernait Postgresql... que je n'apprécie que moyen moyen...
voici donc ma version:
Installation des Packages
Création des comptes systeme
usermod -g www-data otrs
Installation des fichiers OTRS
Cherchez la derniere version stable...
tar xf otrs-3.0.11.tar.gz
mv otrs-3.0.11 otrs && cd otrs
cp Kernel/Config.pm.dist Kernel/Config.pm
cp Kernel/Config/GenericAgent.pm.dist Kernel/Config/GenericAgent.pm
bin/otrs.SetPermissions.pl --otrs-user=otrs --otrs-group=otrs --web-user=www-data --web-group=www-data /opt/otrs
ln -s /opt/otrs/scripts/apache2-httpd.include.conf /etc/apache2/conf.d/otrs.conf
service apache2 restart
Ces instructions vont:
- télécharger la dernière version (3.0.11)
- l'installer dans /opt/otrs
- copier les fichiers de config de distribution pour une utilisation de base
- ajouter les permissions pour l'utilisateur 'otrs' et 'www-data'
- créer le lien symbolique (ln) pour la configuration d'apache et redémarrer le service.
Installation de la base de données
Deux choix s'offrent a vous:
Soit utiliser phpmyadmin (que l'on a installé en premier) c'est simple et intuitif...
- Créez une database otrs.
- Créez un user otrs@localhost lui donner un password otrs...
- donnez tout les droits (grant all) au user otrs sur la database otrs.
Soit le faire a la main. Si vous optez pour la seconde techniquie, voici les commandes...
mysql va vous demander votre mot de passe root (sql) que vous avez donner lors de l'installation. On the psql command line
CREATE DATABASE otrs;
GRANT ALL ON otrs.* TO 'otrs'@'localhost';
QUIT
Dans le shell
mysql -u otrs --password=otrs -D otrs < scripts/database/otrs-initial_insert.mysql.sql
mysql -u otrs --password=otrs -D otrs < scripts/database/otrs-schema-post.mysql.sql
Vérifier la configuration OTRS pour la base de données
nano Kernel/Config.pm
placer votre mot de passe otrs...
# (The password of database user. You also can use bin/otrs.CryptPassword.pl
# for crypted passwords.)
$Self->{DatabasePw} = 'otrs';
Par défaut, OTRS est prévu pour MySQL... Donc vous n'avez plus rien a faire...juste a parcourir la config pour vérifier les bon DB connecteurs...
Configurons le startup apache perl:
Vérifier ces lignes:
use DBD::Pg ();
use Kernel::System::DB::mysql;
Installation des Cron jobs
bin/Cron.sh start otrs
Allez sur la page de votre nouveau systeme pour la configuration 'en ligne'
ouvrez un browser et allez sur http://localhost/otrs/index.pl (ou tout autre url qui mène a ce serveur)
Log in with root@localhost, password root
J'installe Debian
Ayant un nouveau PC, j'ai décidé de me passer de Windows et de faire le pas vers Debian...
Etant un peu frileux quand même, j'ai finalement opté pour un dual boot Windows 7 Pro et Debian 6... pour voir
Comme on peut s'y attendre aucun problème notable avec Windows, Debian, au bout de 4 jours, commence à fonctionner... je vais donc largement étoffé ma section Debian, car j'ai rencontré pas mal de problèmes (logique en fait)
Voici l'histoire, d'une installation réussie...
Debian Squeeze - Nvidia Drivers
On commence avec la carte graphique... NVIDIA... mwouais, c'est pas gagner... GNOME est moche sur un 22" en 1024/768... oui, il ne reconnait pas la carte... logique en fait, puisque NVIDIA fournis Drivers et sources code de ceux-ci mais sous licence propriétaire, ce qui fait que DEBIAN n'intègre rien dans ses dépots "de base"...
il y a beaucoup de méthode qui circulent sur le net... j'en ai essayer pas mal, avant de me fier (avec succès) au constructeur...
Avec succès c'est un bien grand mot... voici mon histoire...
Télécharger sur le site constructeur (NVIDIA) le drivers qui va bien... dans mon cas j'ai choisi les options suivantes:
-
GeForce
-
GeForce 500 Series
-
Linux 64-bit
-
English (US)
j'ai donc ensuite accepter les conditions et télécharger le fichier suivant:
Une fois le téléchargement complet, j'ai invoqué un TTY (CTRL-ALT-F1), je m'y suis loggué en tant que root.
J'ai stoppé le serveur X:
et j'ai lancé l'execution de l'installation:
Après les menus et agrement d'usage, je suis tombé sur un message hermétique
The compiler used to compile the kernel (gcc 4.3) does not exactly match the current compiler (gcc 4.4). The Linux 2.6 kernel module loader re jects kernel modules built with a version of gcc that does not exactly match that of the compiler used to build the running kernel.
If you know what you are doing and want to ignore the gcc version check, select "No" to continue installation. Otherwise, select "Yes" to abor t installation, set the CC environment variable to the name of the compiler used to compile your kernel, and restart installation.
Abort now?
Si on ignore l'erreur, cela ne marche pas... j'ai pas mal galérer pour comprendre... que c'était completement idiot, voici les commandes a faire:
ln -s /usr/bin/gcc-4.3 /usr/bin/gcc
sh NVIDIA-Linux-x86_64-295.53.run
rm /usr/bin/gcc
ln -s /usr/bin/gcc-4.4 /usr/bin/gcc
En gros, cela change le lien symbolique gcc de la version 4.4 (actuelle) vers la version 4.3 (ln...) puis cela execute l'installation des drivers, et enfin on restore le lien symbolique gcc vers la version actuelle 4.4
a la fin de l'installation un startx permet de controler la bonne réalisation... c'est con... mais j'y ai passé la soirée...
Mount a gogo
Petit aide mémoire pour la commande mount dans tous les sens...surtout entre serveurs
mount windows Network Share
temporary mount:
ou si vous disposé d'un fichier de connection.
permanent mount:
etitez /etc/fstab, et ajouter cette ligne:
credentials file:
si vous placez le ficher .smbcredentials dans un home dir, seulement cet utilisateur (eventuellement le root) peut monter ce disque "automatique"
exemple de /root/.smbcredentials
password=[PASSWORD]
domain=[DOMAIN_OR_WORKGROUP]
n'oubliez pas de chmoder le fichier pour qu'il soit lisible seulement par le root...
mount path through ssh
mounting server/remote/path on /mnt/localPath/
partie Serveur
s'assurer que "user" peut faire du ssh (voir le fichier sshd.ini) et qu'il puisse lire le dossier a monter, sinon ca marche pas
partie Client
install sshfs
modprobe fuse
mount first time (for key)
umount /mnt/localPath/
Exemple:
n'oubliez pas les ':' entre le host et le "remote directory"
make public key
-> ne remplissez pas de "passphrase" a moins que vous ne désirez entrer cette "passphrase" a chaque mount, c'est bien pour la sécurité d'en mettre une, moins pratique pour un mount automatique... A vous de voir.
Installer la clé sur le serveur distant (pour pouvoir s'autentifier directement)
il faut fournir le mot de passe de l'utilisateur "cible" sur le serveur "cible"
On the Server
checker la clé générée
vous devez trouver un tas de chiffres et de lettres (la clé) avec à la fin de la ligne: remote_user@remote_client (usually root@remote_client_ip_or_name).
vous pouvez aussi controller toutes les "clés" déjà ajoutées
On the Client
check ssh
Cela doit ouvrir un shell ssh SANS mot de passe
edit the fstab pour automatiser le mount
user_name@servername-or-ip:/remote/path /mnt/localPath fuse.sshfs defaults,_netdev 0 0
Mount read-only NTFS
Mounting macOSX filesystem
install "drivers"
mount drive in Read Only
mount -o ro /dev/hdxx /media/loop -t hfsplus
dismount
OPENERP 7 et Debian
petit pense bête pour l'installation d'OpenERP 7
sur une installation clean (sans serveur apache ni rien...)
pré-requis python:
pré-requis postgresql:
recupération et installation du dernier build debian:
dpkg -i openerp_7.0-latest-1_all.deb
VMWare Tools sous Debian 6/7/8
Comme chacun le sais, Debian c'est pour les serveurs...
Donc si vous devez déployer des distro linux sur des machines virtuelles, il est mieux d'avoir les VMWare Tools installer (pour profité des accélérations, de la bonne surveillance de votre serveur par VSphere et aussi de la bonne gestion de la souris, mais bon ça, sur un serveur CLI on s'en fout un peu).
[UPDATE]
il y a plus facile que d'installer les vmtools, il existe un paquet open-vm-tools qui fait le café en 2 lignes de commande.
Si vous voulez l'intégré aux updates du kernel et ne pas vous soucier des version gnu/kernel, n'hésitez pas, choisisez la version dkms:
Si votre VM est équipé d'un environement "desktop"...
[/UPDATE]
Si vous préférez la version barbue :
Pour pouvoir installer correctement les VMware Tools, certains packages sont nécessaires (notamment les entêtes du noyau Linux et un compilateur C avec la bonne version).
On commence par vérifier avec quel version de compilateur C votre noyau a été compilé et la version de votre Linux :
Linux version 2.6.32-5-686 (Debian 2.6.32-31) (ben@decadent.org.uk) (gcc version 4.3.5 (Debian 4.3.5-4) ) #1 SMP Tue Mar 8 21:36:00 UTC 2011
Maintenant, on installe les packages nécessaires au bon fonctionnement de VMware Tools :
root@srv-zeus::~# apt-get install cpp gcc-4.3*
root@srv-zeus:~# apt-get install linux-headers-$(uname -r)
La commande uname -r demande de fournir seulement le kernel-release, cette commande sera TOUJOURS conforme a votre système.
Montez le fichier ISO des VMWare Tools (via la commande classique, Guest -> Install/Upgrade VMWare Tools
root@srv-zeus:~# cp /media/cdrom/VMwareTools-8.4.5-324285.tar.gz /root/
root@srv-zeus:~# tar xvfz VMwareTools-8.4.5-324285.tar.gz
root@srv-zeus:~/vmware-tools-distrib# ./vmware-install.pl
Creating a new VMware Tools installer database using the tar4 format.
Installing VMware Tools.
In which directory do you want to install the binary files?
[/usr/bin]
What is the directory that contains the init directories (rc0.d/ to rc6.d/)?
[/etc]
What is the directory that contains the init scripts?
[/etc/init.d]
In which directory do you want to install the daemon files?
[/usr/sbin]
In which directory do you want to install the library files?
[/usr/lib/vmware-tools]
In which directory do you want to install the documentation files?
[/usr/share/doc/vmware-tools]
The path "/usr/share/doc/vmware-tools" does not exist currently. This program
is going to create it, including needed parent directories. Is this what you
want? [yes]
The installation of VMware Tools 8.4.5 build-324285 for Linux completed
successfully. You can decide to remove this software from your system at any
time by invoking the following command: "/usr/bin/vmware-uninstall-tools.pl".
Before running VMware Tools for the first time, you need to configure it by
invoking the following command: "/usr/bin/vmware-config-tools.pl". Do you want
this program to invoke the command for you now? [yes]
Initializing...
The path "/usr/bin/gcc-4.3" appears to be a valid path to the gcc binary.
Would you like to change it? [no]
....
....
/etc/init.d/networking start
Enjoy,
--the VMware team
Et Voila le travail...
Microsoft Windows (Servers et Clients)




Microsoft Exchange
Exchange 2007 : Indexation et recherche dans les mailboxes
Le moteur de recherche d'Exchange 2007 a été nettement amélioré par rapport aux moteurs d'indexation/recherches qui étaient disponibles dans Exchange 2000/2003. La nouvelle version est moins gourmande en ressources, plus rapide, effectue des recherches à l'intérieur des pièces jointes, et il est active dès l’installation.
Activer/désactiver "search"
Pour activer ou désactiver la recherche Exchange, ouvrez Exchange Management Shell
Exécutez la commande suivante pour voir si la recherche est activé sur une boîte aux lettres spécifique:
ou créer une liste des mailboxes par base de données où la fonction est activée:
Pour activer la fonction:
Pour la désactiver:
Pour désactiver la fonction completement sur le serveur, il suffit de stopper le service d'Indexation:
Gardez à l'esprit que si vous exécutez Outlook 2007 en mode "cached", la recherche "Exchange" n'est pas disponible. La recherche est traitée par le service local du PC client. Dans Outlook 2003, le logiciel effectue une analyse linéaire de chaque message (un par un).
Tester la fonctionnalité "Search"
Il existe une commande powershell qui vous permet de tester si la recherche / indexation fonctionne comme prévu. Par défaut, le délai d'attente de réponse est réglé sur 60 secondes, mais en réalité, vous devriez obtenir des résultats en moins de 10 secondes. (de sorte que vous pouvez éventuellement accélérer le test en fixant un délai de réponse de 20 secondes ou plus, ce qui vous permettra de tester une plus grande part de boîtes aux lettres à l'aide d'un script, en moins de temps.
Utilisez la commande suivante pour exécuter un test sur toutes les boîtes aux lettres sur votre serveur:
Vous allez voir dans votre fenêtre powershell une bar de progression de la fonction de test: "TestSearch"
Lorsque "ResultFound" réponds "Faux" et le champ "SearchTime" donne un résultat de "-1", alors la recherche ne fonctionne pas pour cette boîte aux lettres.
Faites attention aux éventuelles erreurs (autres) lors de l'exécution de cette commande. Elles devraient vous donner des informations plus précises quand a la(les) raison(s) pour laquelle(lesquelles) la recherche ne fonctionne pas pour une boîte aux lettres donnée.
Si vous avez des bases de données multiples, vous pouvez utiliser le script suivant pour limiter le critère à seulement une base de données qui vous intéresse:
Que faire si "Search" ne fonctionne pas ?
Outlook Web Access : Si vous recevez un message qui dit: "results will take a long time to appear because Microsoft Exchange Search is unavailable. Results will not include matches in the e-mail body", dans ce cas, il se peut que vous ayez un indexe corrompu.
Parfois, quand vous migrez (ou créez) des mailboxes, les premiers résultats de l'indexations sont fait "dans le vide" ou sur une partie non encore initialisée, ce qui produit un indexe corrompu.
Utilisez la commande PowerShell pour exécuter un test de recherche sur chaque boîte aux lettres (comme expliqué plus haut dans ce post). Regardez la colonne "ResultFound" et le "SearchTime". Vous devriez voir un problème pour l'utilisateur qui a signalé le problème.
Les index de recherche ne sont (heureusement) pas stockées dans les bases de données Exchange. Les données d'indexation sur une base de données spécifique sont stockées dans un répertoire sur le même emplacement que les fichiers de base de données.
Le nom du répertoire suit la convention CatalogData-<guid>-<guid>, où le <guid> premier est le GUID de la base de données et le second représente le <guid> d'instance, instance qui est utilisée dans les scénarios de cluster exchange de marquer une distinction entre les nœuds . Ce qui suit est un exemple de nom de dossier:
Le chemin typique (ou par défaut) pour les fichiers ".edb" et les fichiers du répertoire CatalogData est: C:\Program Files\Microsoft\Exchange Server\ Mailbox\First Storage Group\
L'index de recherche peut être non synchronisé avec la base de données après une reprise de crash ou de démontage forcé de la base de données (en cas de dépassement de taille de base de données par exemple), et que les fichiers de transaction (transaction logs) sont ré-appliqué sur la base de données. Le moteur de recherche Exchange ne lit pas les fichiers journaux joué pour l'indexation.
J'ai aussi vu des cas où l'indice a été corrompu pendant ou après le déplacement de la boîte aux lettres à partir d'un serveur 2003 vers un serveur 2007. Dans ces situations, vous devez reconstruire le catalogue d'index de recherche.
Vous pouvez procéder comme ceci pour reconstruire un catalogue d'indexe.
- Arretez le service "Microsoft Exchange Search indexer"
- Détruisez le catalogue en cause (n'hésitez pas a utiliser la commande powershell pour confirmer le nom du catalogue "GetSearchIndexForDatabase –all")
- Relacer le service "Microsoft Exchange Search indexer.
Il existe aussi une procédure powershell qui effectue les même action pour vous:
ResetSearchIndex -Force -All (si vous désirez effectuer l'opperation sur TOUTES vos base de données)
WARNING: Waiting for service ‘Microsoft Exchange Search Indexer (MSExchangeSearch)’ to finish stopping…
WARNING: Waiting for service ‘Microsoft Exchange Search Indexer (MSExchangeSearch)’ to finish stopping…
WARNING: Waiting for service ‘Microsoft Exchange Search Indexer (MSExchangeSearch)’ to finish stopping…
MSExchangeSearch service stopped
removing: D:\Exchange Server\Mailbox\First Storage Group\CatalogData-fb802b8a-fd2a-4da2-9dc5-7dc41c398409-cc64dd2d-2428-4f12-bba2-79d6d34c4d27
Confirm
Are you sure you want to perform this action?
Performing operation "Remove Directory" on Target "D:\Exchange Server\Mailbox\First Storage Group\CatalogData-fb802b8a-fd2a-4da2-9dc5-7dc41c398409-cc64dd2d-2428-4f12-bba2-79d6d34c4d27".
[Y] Yes [A] Yes to All [N] No [L] No to All [S] Suspend [?] Help
(default is "Y"):A
MSExchangeSearch service Started
Note : vous pouvez utilisez le paramètre -all de la commande ResetSearchIndex.ps1 pour effacer et reontruire l'indexe pour toutes les mailboxes.
Maintenant vous pouvez executer la commande Test-ExchangeSearch a nouveau pour voir les résultat et confirmer la bonne résolution du problème.
Astuce : Voir le statut de votre Base de données
JournalRecipient :
MailboxRetention : 30.00:00:00
OfflineAddressBook : \Default Offline Address List
OriginalDatabase :
PublicFolderDatabase : SERVER\Second Storage Group\Public Folder Datab
ase
ProhibitSendReceiveQuota : 2355MB
Recovery : False
ProhibitSendQuota : 2GB
IndexEnabled : True
AdministrativeGroup : Exchange Administrative Group (XXXXXXXXXXXXXXX)
AllowFileRestore : False
BackupInProgress : False
CopyEdbFilePath :
DatabaseCreated : True
Description :
EdbFilePath : D:\Exchange Server\Mailbox\First Storage Group\
Mailbox Database.edb
ExchangeLegacyDN : /o=organization/ou=Exchange Administrative Group (XXXXXXXXXXXXXXX)/cn=Configuration/cn=Serve
rs/cn=APOLLO/cn=Microsoft Private MDB
HasLocalCopy : False
DeletedItemRetention : 14.00:00:00
LastFullBackup : 19/09/2007 3:03:30
LastIncrementalBackup :
MaintenanceSchedule : {zo.1:00-zo.5:00, ma.1:00-ma.5:00, di.1:00-di.5
:00, wo.1:00-wo.5:00, do.1:00-do.5:00, vr.1:00-
vr.5:00, za.1:00-za.5:00}
MountAtStartup : True
Mounted : True
Organization : organization
QuotaNotificationSchedule : {zo.1:00-zo.1:15, ma.1:00-ma.1:15, di.1:00-di.1
:15, wo.1:00-wo.1:15, do.1:00-do.1:15, vr.1:00-
vr.1:15, za.1:00-za.1:15}
RetainDeletedItemsUntilBackup : False
Server : SERVER
ServerName : SERVER
StorageGroup : SERVER\First Storage Group
StorageGroupName : First Storage Group
IssueWarningQuota : 1945MB
EventHistoryRetentionPeriod : 7.00:00:00
Name : Mailbox Database
MinAdminVersion : -2147453113
AdminDisplayName : Mailbox Database
ExchangeVersion : 0.1 (8.0.535.0)
DistinguishedName : CN=Mailbox Database,CN=First Storage Group,CN=InformationStore,CN=SERVER,CN=Servers,CN=Exchange Administrative Group (XXXXXXXXXXXXX),CN=Administrative Groups,CN=organization,CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=dc1,DC=dc2
Identity : SERVER\First Storage Group\Mailbox Database
Guid : fb8152b8a-f47a-4bae-914d-7ebda1c397809
ObjectCategory : dc1.dc2/Configuration/Schema/ms-Exch-Private -MDB
ObjectClass : {top, msExchMDB, msExchPrivateMDB}
WhenChanged : 11/09/2007 20:11:58
WhenCreated : 11/09/2007 20:10:37
OriginatingServer : server.dc1.dc2
IsValid : True
Source:
http://www.corelan.be/index.php/2007/09/19/exchange-2007-indexing-and-searching-mailboxes/
http://technet.microsoft.com/en-us/library/aa995966.aspx
http://www.exchangeninjas.com/ExchangeSearchFAQ
Distribution List ET Sécurity Group
Sous Windows 2000, il fallait faire une Distribution List pour le courrier et Créer aussi un group de sécurity pour gérer les sécurités sur le FilesSystem... en 2008 (avec Exchange 2007) plus de problèmes... a condition que le schéma de votre AD soit au moins 2003...( c'est mon cas en tout les cas).
Il est possible de transformé une Distribution List en Security group...
- Dans Active Directory for Users and Computers (ADUC pour les intimes), sélectionnez la liste a transformer...
- Choisir “properties” et cochez "security groups" (au lieu de "Distribution List").... faire « OK »
- Elle devient donc « Security Group – Universal » avec une adresse email...
Un rapide check dans la console Exchange, le type devient « Mail-Enabled Universal Security Group ».
On peut lui envoyer des emails (comme avant) ET le sélectionner pour limiter les accès à un Folder (ou une resources)...
GPO: Deployer un certificats authority
Quand vous décidez d’installer un certification pour sécuriser un serveur, il faut ensuite déployer les certificats chez tous les clients... Souvent on réalise cela poste par poste... mais il y a moyen de faire plus simple...
Pour ne pas perdre de temps lors de l’installation des certificats ordinateurs et utilisateurs, il est possible de paramétrer l’inscription automatique des certificats pour un domaine à l’aide de GPO.
Pour cela on se connecte sur GPMC (Group Policy Management Console), cela se déroule en 2 étapes :
1ère Étape : Configuration de l'Ordinateur
- Sous le nom de domaine concerné, dans l'unité d'organisation désirée, on choisi l'une des policies, ou on crée une nouvelle...
- Ensuite il faut déplier Computer Configuration > Windows Settings > Security Settings > Public Key Policies
- Ensuite il faut double-cliquer sur Autoenrollment Settings, sélectionner Enroll certificates automatically (coché par défaut) et cocher les deux options qui sont en dessous (renouveler et mettre à jour)
- Dans Automatic Certificate Request Settings, faire click droit > New > Automatic Certificate Request...
- Faire suivant et sélectionner Computer puis terminer
- Dans Trusted Root Certification Authorities, faire click droit > Import... Choisir le certificat à Importer
2ème Étape : Configuration Utilisateur
- Il faut déplier User Configuration > Windows Settings > Security Settings > Public Key Policies
- Ensuite il faut double-cliquer sur Autoenrollment Settings, sélectionner Enroll certificates automatically (coché par défaut) et cocher les deux options qui sont en dessous (renouveler et mettre à jour)
Voilà le déploiement des certificats se fera lorsque la mise à jour des GPO se lancera, vous pouvez forcer la mise à jour des GPO en lançant :
gpupdate /sync ou /force si vous voulez forcer la mise à jour. Pour voir si les certificats ont bien été déployer on peut lancer la commande gpudate sur un client et ensuite voir dans la mmc autorité de certification si les certificats apparaissent.
RoboCopy : Robust File Copy
RoboCopy ne veut pas dire Robot de Copie, mais bien Robust File Copy...
vous pouvez utiliser ce logiciel pour copier, déplacer (migrer), mirrorer etc... des fichiers, dossiers voir même des disques entiers, suivant votre envie...
ROBOCOPY :: Robust File Copy for Windows :: Version XP010
-------------------------------------------------------------------------------
Started : Mon Jul 23 17:16:17 2012
Usage :: ROBOCOPY source destination [file [file]...] [options]
source :: Source Directory (drive:\path or \\server\share\path).
destination :: Destination Dir (drive:\path or \\server\share\path).
file :: File(s) to copy (names/wildcards: default is "*.*").
::
:: Copy options :
::
/S :: copy Subdirectories, but not empty ones.
/E :: copy subdirectories, including Empty ones.
/LEV:n :: only copy the top n LEVels of the source directory tree.
/Z :: copy files in restartable mode.
/B :: copy files in Backup mode.
/ZB :: use restartable mode; if access denied use Backup mode.
/COPY:copyflag[s] :: what to COPY (default is /COPY:DAT).
(copyflags : D=Data, A=Attributes, T=Timestamps).
(S=Security=NTFS ACLs, O=Owner info, U=aUditing info).
/SEC :: copy files with SECurity (equivalent to /COPY:DATS).
/COPYALL :: COPY ALL file info (equivalent to /COPY:DATSOU).
/NOCOPY :: COPY NO file info (useful with /PURGE).
/PURGE :: delete dest files/dirs that no longer exist in source.
/MIR :: MIRror a directory tree (equivalent to /E plus /PURGE).
/MOV :: MOVe files (delete from source after copying).
/MOVE :: MOVE files AND dirs (delete from source after copying).
/A+:[RASHNT] :: add the given Attributes to copied files.
/A-:[RASHNT] :: remove the given Attributes from copied files.
/CREATE :: CREATE directory tree and zero-length files only.
/FAT :: create destination files using 8.3 FAT file names only.
/FFT :: assume FAT File Times (2-second granularity).
/256 :: turn off very long path (> 256 characters) support.
/MON:n :: MONitor source; run again when more than n changes seen.
/MOT:m :: MOnitor source; run again in m minutes Time, if changed.
/RH:hhmm-hhmm :: Run Hours - times when new copies may be started.
/PF :: check run hours on a Per File (not per pass) basis.
/IPG:n :: Inter-Packet Gap (ms), to free bandwidth on slow lines.
::
:: File Selection Options :
::
/A :: copy only files with the Archive attribute set.
/M :: copy only files with the Archive attribute and reset it.
/IA:[RASHCNETO] :: Include only files with any of the given Attributes set.
/XA:[RASHCNETO] :: eXclude files with any of the given Attributes set.
/XF file [file]... :: eXclude Files matching given names/paths/wildcards.
/XD dirs [dirs]... :: eXclude Directories matching given names/paths.
/XC :: eXclude Changed files.
/XN :: eXclude Newer files.
/XO :: eXclude Older files.
/XX :: eXclude eXtra files and directories.
/XL :: eXclude Lonely files and directories.
/IS :: Include Same files.
/IT :: Include Tweaked files.
/MAX:n :: MAXimum file size - exclude files bigger than n bytes.
/MIN:n :: MINimum file size - exclude files smaller than n bytes.
/MAXAGE:n :: MAXimum file AGE - exclude files older than n days/date.
/MINAGE:n :: MINimum file AGE - exclude files newer than n days/date.
/MAXLAD:n :: MAXimum Last Access Date - exclude files unused since n.
/MINLAD:n :: MINimum Last Access Date - exclude files used since n.
(If n < 1900 then n = n days, else n = YYYYMMDD date).
/XJ :: eXclude Junction points. (normally included by default).
::
:: Retry Options :
::
/R:n :: number of Retries on failed copies: default 1 million.
/W:n :: Wait time between retries: default is 30 seconds.
/REG :: Save /R:n and /W:n in the Registry as default settings.
/TBD :: wait for sharenames To Be Defined (retry error 67).
::
:: Logging Options :
::
/L :: List only - don't copy, timestamp or delete any files.
/X :: report all eXtra files, not just those selected.
/V :: produce Verbose output, showing skipped files.
/TS :: include source file Time Stamps in the output.
/FP :: include Full Pathname of files in the output.
/NS :: No Size - don't log file sizes.
/NC :: No Class - don't log file classes.
/NFL :: No File List - don't log file names.
/NDL :: No Directory List - don't log directory names.
/NP :: No Progress - don't display % copied.
/ETA :: show Estimated Time of Arrival of copied files.
/LOG:file :: output status to LOG file (overwrite existing log).
/LOG+:file :: output status to LOG file (append to existing log).
/TEE :: output to console window, as well as the log file.
/NJH :: No Job Header.
/NJS :: No Job Summary.
::
:: Job Options :
::
/JOB:jobname :: take parameters from the named JOB file.
/SAVE:jobname :: SAVE parameters to the named job file
/QUIT :: QUIT after processing command line (to view parameters).
/NOSD :: NO Source Directory is specified.
/NODD :: NO Destination Directory is specified.
/IF :: Include the following Files.
Voici une ligne de commande magique pour "mirrorer" deux dossiers, et loggué le résultat dans un fichier:
Cela produira un fichier log de ce type:
ROBOCOPY :: Robust File Copy for Windows :: Version XP010
-------------------------------------------------------------------------------
Started : Wed Jul 25 10:04:20 2012
Source : S:\source\Part3\
Dest : P:\target\Part3\
Files : *.*
Options : *.* /X /NFL /TEE /S /E /COPY:DATS /NP /R:1000000 /W:30
------------------------------------------------------------------------------
0 S:\source\Part3\
0 S:\source\Part3\2009\
0 S:\source\Part3\2009\09-03\
0 S:\source\Part3\2009\09-03\B\
2 S:\source\Part3\2009\09-03\B\113\
1 S:\source\Part3\2009\09-03\B\114\
:
Windows 7 Pro : Changer la langue (par defaut) de l'utilisateur
Windows 7 Pro est différent de son prédessesseur, en ce qu'il n'autorise pas le changement de langue...(entre autre)
Bref, vous avez acheter un Windows 7 (argh) Proffessionnal (re-argh) et il vous est gentillement livré en français/neerlandais... mais vous en vrai baroudeur vous préférez l'anglais... vous l'avez où je pense...
sauf, sauf si vous bidouillez un peu...
- Récupérez le language pack : en-us/lp.cab sur le Language Pack DVD, ou téléchargez-le depuis MSDN
- Créez un dossier c:\MLP et copiez y le sous dossier qui va bien, ici en-us
Vous devriez donc avoir quelques chose comme ceci:
MLP\
en-US\
lp.cab
- Ouvrez une cmd en mode administrator (c'est TRES important) et tapez la commande suivante
Son execution va prendre un certains temps (cela ne dépends pas de la puissance de la machine... soyez donc patient.
Cette commande ajoute a l'image "online" (en cours d'utilisation) le package en question...
- A ce point rien n'est encore fait, le package est installé mais pas spécifié ni utiliser.
Il faut donc informé windows que vous désirez utilisé un autre "locale".
Voici comment y remédier:
- Même chose pour le boot loader (sinon il "causera" toujours la même langue)
Pour ce faire,ouvrez RegEdit et naviguez jusqu'a la clé suivante:
- Redémarrer votre PC, il sera en anglais...
Notes, que vous devrez peut-etre forcer une mise a jour Windows avant de continuer...
Bon changement...
détourner une adresse IP
A mon travail, pour des raisons légitimes, j'ai eut besoin de détourer une IP d'un host "public" vers un serveur interne.
Mes utilisateurs doivent utiliser une resource interne qui est aussi accessible via un gateway externe, mais pas sur la même adresse IP, en effet un poste LAN n'a pas accès directement a Internet (il n'est même pas NATé).
La source de ce besoin est un problème de firewall, je ne veux pas que, pour utiliser un serveur particulier "toto.domain.com", le traffic de mes utilisateurs traverse mon firewall pour sortir vers le serveur en question, y génère une charge élevée, et re-rentre dans le système via une sorte de loop-back.
Mon domain.com n'est pas géré en interne, mais chez un prestataire externe; donc difficile pour moi d'en avoir une copie toujours à jour, et de maintenir un "faux" domaine en interne, de plus je n'ai en fait aucune envie de maintenir "deux" domain.com.
Description
Mes utilisateurs doivent accéder à une resource local "toto.domain.local" depuis le réseau interne; mais aussi depuis le réseau externe "toto.domain.com".
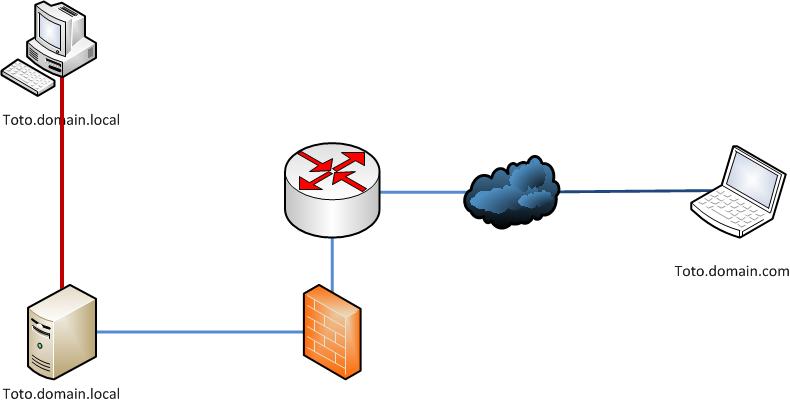
Evidement, il arrive souvent qu'un utilisateur se trompe de coté (essaye toto.domain.com sur son PC corporate et qu'il reçoit un Time out) où l'inverse; le résultat est le même, l'utilisateur ne sait pas se connecter, il est frusté, il s'énerve et ne comprends pas pourquoi ca ne marche pas, et surtout il ne pense pas plus loin, j'ai bien essayé des les éduquer... Sans succès, cela leurs demande bien trop d'effort de réfléchir.
Je ne suis pas pour le nivellement par le bas, mais là, j'abandonne à la facilité, je vais trouver une solution facile et élégante, ne pouvant pas "mirrorer presque tout le domain.com sur un DNS "local" (et ne voulant pas gérer les deux domaines avec le risque de confondre les domaines interne et externe, il me fallait ruser.
Solution 1
Ma première idée, a été d'autoriser les utilisateurs "LAN" a sortir pour re-renter ensuite... (Mais j'ai changé d'avis très vite).
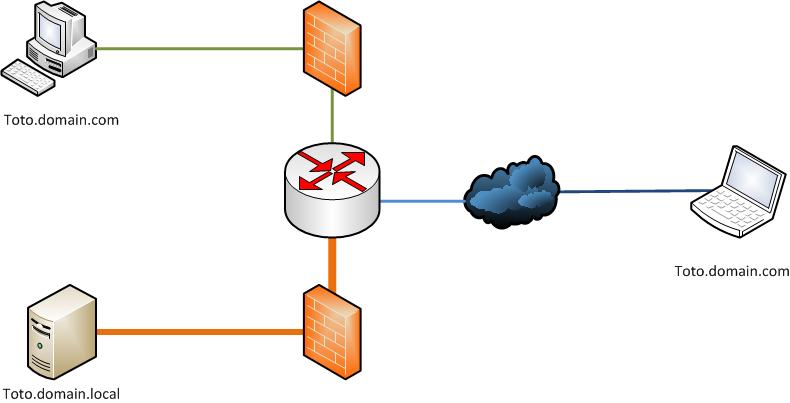
D'abord c'est horrible comme construction, ensuite, c'est une faille de sécurité non négligeable, puisque les utilsateurs pourront sortir (et envidement rentrer) pour cette adresse (ce qui veut dire aussi que, potentiellement, un hacker pourrait spoofer mes IPs et tromper le Firewall en entrée).
Pour ajouter au désinteret de cette idée, cela induit une charge CPU sur les firewalls et les routers qui n'est pas négligeable. Tout cela parceque les utilisateurs sont "idiots"...
Idéalement il faudrait que le PC prenne l'IP "toto.domain.local" quand on tape "toto.domain.com"; dans mon cas c'est assez facile sur un PC de changer le fichier hosts du PC LAN, mais je vois plusieurs inconveniant a cela:
- A l'exterieur du LAN, un portable continuera a chercher l'IP "toto.domain.local" en lieu et place du "toto.domain.com"
- Quand on n'a que un ou deux PC c'est pas un problème, mais 200-500 ou plus ca devient l'enfer à déployer
- En cas de modification de l'IP du serveur, il faut TOUT refaire sur tout les PC
En fait, s'il est relativement facile de faire cela chez soi via le fichier hosts sur quelques PC avec des gens "compréhensifs" comme peut l'être la famille; c'est quasi impossible sur un réseau complexe et/ou avec des DNS Windows 2008R2.
J'ai donc rejeté cette Solution
Solution 2
J'ai donc imaginé de mettre en place ce fameux fichier hosts sur mes DNS serveurs, sauf que les DNS serveur de Windows 2008 se foutent pas mal du fichier hosts pour faire leur boulot, il se basent sur les zones définies et, à défaut, sur les forwarder.
J'ai essayé de faire une zone secondaire pour mon domain.com, mais là c'est devenu l'enfer pour d'autres IP/serveurs... car les A/CNAME/MX records de domaine n'existent pas dans mon "faux" domain.com... ce qui produit un effet "server not found" très dégueulasse...
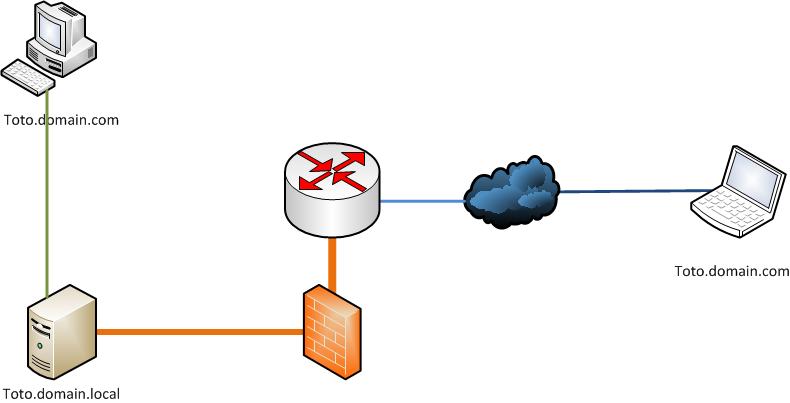
J'ai tenté la zone "stub" sans succès... puis le trait de génie:
Créer une zone primary toto.domain.com, avec un record A sans nom qui pointe vers mon serveur toto.domain.local.
Cerise sur le gateau, je peux créer des zones secondaires sur tous les DNS serveurs internes qui se répliquent sur ce serveur maître.
Et là, O miracle, les PC dans le LAN résolvent via leurs serveurs normaux (fournis par DHCP) la bonne adresse INLAN; et hors LAN, ils resolvent bien via les serveurs de leurs providers l'adresse publique:
Bien sur cela fonctionne aussi pour détourner, dans votre LAN, n'importe quelle adresse IP (et donc url tapée dans un browser) vers l'un de vos serveurs, je me suis beaucoup amusé à détourner facebook.com vers un serveur apache qui affichait ce texte:
LA CIA écoute ce que vous écrivez sur ce site.
Après analyse des statisques de connections, la CIA vous informe que votre quota Facebook est dépassé.
La tête et la réaction des utilisateurs visés fut un grand moment de rigolade en somme.
I fallait que je me défoule sur les responsables de mon calvaire.
VMWare ESX(i) 4, 5 et Workstation
![]()
Depuis bientôt deux ans, j'utilise vmware comme base pour la consolidation et virtualisation des serveurs a mon bureau.
Je connais VMWare depuis bien plus longtemps que ca, en 1997 ou 1998, nous utilisions VMWare Workstation comme laboratoire virtuel pour le développement, ainsi que pour faire tourner de vieux jeux DOS qui ne supportaient pas Windows NT, ou certaines applications qui ne fonctionnaient pas avec la mythique Gravis Ultra Sound (GUS) [1].
La version ESX 5 offre pas mal de (bonnes) nouveautées, citons en quelques unes:
- bonne optimisation des VM 64x (principalement en Windows 2008-2008 R2, 7). Les VMs sous debian semble moins impactées par ces optimisations; faut bien dire que la console sous 2008 en ESX 4 ramaient sévère.
- Amélioration de la gestion AERO, là aussi on attendait largement une révision des drivers graphiques de VMWare.
- intégration des OSX en mode natif, donc plus aucun "expoit" a installer un OSX sur VMWare (grrr) quoi que...
- Gestion des volumes VMFS de plus de 2 TB (enfin)
Parmis les "mauvaises" surprises:
- changement du systeme de licences, la mémoire RAM est également prise en compte, plus uniquement les CPUs (physiques), cela semble toutefois moins lourds qu'annoncer
- Le vCenter qui passe en 64bits uniquement (bonjour l'extra licence windows 2008 pas prévue dans le budget)
Je parlerais aussi de son petit frère; la version Workstation (et de l'outsider VirtualBox)
[1] Note pour moi-même, je ferais bien un article sur cette carte exceptionnelle.
[ESX4] OSX sous VMWare (Esx 4.1)
Je vais faire un 'how-to' un de ces quatres, mais voici une petite fiertée... il parrait que ce n'est pas si simple finalement...
[ESX] Authoriser la connection root en ssh
Ca y est, votre ESX est correctement configuré (ou peu s'en faut), vous devez vous connecter pour finaliser deux trois détails, pour avoir une console plus grande, et un meilleurs confort (en effet les serveurs sont a la cave, difficile d'accès ou leurs consoles 'local' n'est même pas cablée, vous choisisez d'utiliser 'ssh'... et votre password 'root' ne fonctionne pas... (alors que le même mot de passe utiliser plutot sur la console local fonctionne bien)
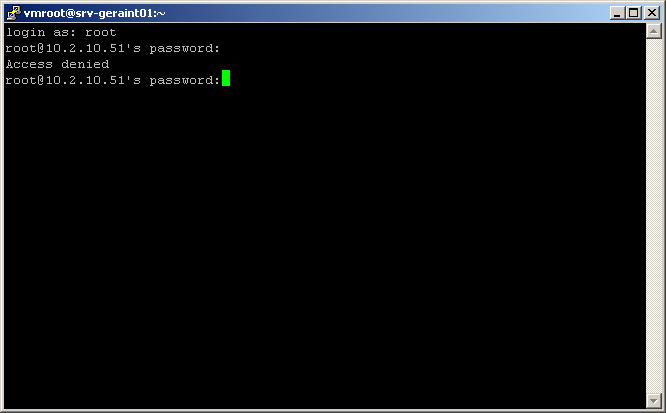
Mais pourquoi dites vous... Etes vous fatigué a ce point d'avoir taper un mauvais mot de passe... ou bien est ce que l'ESX refuserait le login en ssh pour le root ?
C'est en fait cette derniere option qui est la bonne... depuis la version 3 des ESX, pour augmenter la sécurité, il est impossible de se connecter en root via le service ssh, si votre ESX est accessible a tous via n'importe quoi; c'est effectivement une bonne solution, mais si vous penser que c'est un peu 'too much' alors voici la marche a suivre.
Si vous avez créer lors de l'installation un autre compte connectez vous en ssh avec
votre premiere commande sera de passer en mode root:
Si vous n'avez pas créer de compte 'de secours'; vous n'avez alors pas d'autre choix que de vous connectez s en root sur la console du host (ou de créer un compte via le client vSphere pour ensuite vous connecter avec).
Editez ensuite le fichier de configuration du deamon ssh, avec la commande suivante par exemple
Chercher la ligne PermitRootLogin no et changer le 'no' en 'yes'; sauvegarder les changements (Ctrl-O); nano va vous proposer d'éditer le nom du fichier a sauvegarder, ne changez rien; et pressez Enter, vous pouvez quitter nano avec Ctrl-X.
Il ne vous reste plus qu'a redémarrer votre deamon ssh:
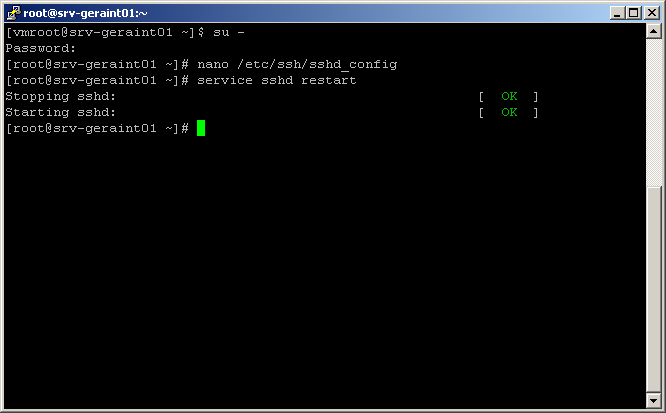
Et voila
[ESX] Connecter le service console a un vlan APRES installation
Si comme moi, vous avez une configuration ESX un peu complexe, vous avez plus que certainement des VLANs pour la gestion du "reseau"... et vous n'utilisez pas le même VLAN que celui par défaut, dans mon cas le VLANID est 1, de même le vMotion est sur le VLANID 10.
Si comme moi, lors de l'installation de votre ESX en mode 'next-next-config-next'; vous avez peut-etre raté la configuration du VLAN, et que vous ne savez pas connecter votre nouveau ESX via le network; il va falloir pratiquer la configuration unix; ceux qui connaissent Debian, redhat ou centos, sans la version graphique, savent de quoi je parle, pour les autres; voici comment configurer votre System Console -> LAN.
connectez vous en root, sur la console physique du serveur (via le réseaux, ce n'est pas encore possible acause de votre oubli)
ESX utilise une carte réseau virtuelle pour se connecter, un simple ifconfig vous le prouvera; outre le traditionnel lo (pour loopback), vous allez voir l'ensemble de vos interfaces physiques nommés 'vmnicx' ainsi qu'un interface au nom étrange: vswif0; il s'agit de votre interface 'service console' qui par défaut est rataché a l'interface que vous avez précisé lors de l'instalation
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:4539 errors:0 dropped:0 overruns:0 frame:0
TX packets:4539 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:10178211 (9.7 MiB) TX bytes:10178211 (9.7 MiB)
:
vmnic3 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7004 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:861771 (841.5 KiB) TX bytes:0 (0.0 b)
Interrupt:201
vswif0 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
inet addr:10.2.10.51 Bcast:10.2.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8970 errors:0 dropped:0 overruns:0 frame:0
TX packets:6363 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1711522 (1.6 MiB) TX bytes:5477550 (5.2 MiB)
Switch Name Num Ports Used Ports Configured Ports MTU Uplinks
vSwitch0 64 1 32 1500 vmnic2
PortGroup Name VLAN ID Used Ports Uplinks
Service Console 0 1 vmnic2
VMotion 1 0 vmnic2
# esxcfg-vswitch -v 10 -p VMotion vSwitch0
Switch Name Num Ports Used Ports Configured Ports MTU Uplinks
vSwitch0 64 1 32 1500 vmnic2
PortGroup Name VLAN ID Used Ports Uplinks
Service Console 1 1 vmnic2
VMotion 10 0 vmnic2
[ESX] Conseils d'installation: SNMP bavard
Lors de la configuration d'un host ESX, il y a certaines options qui peuvent vous pourrir la vie... ou plutôt remplir des logs de truc inutiles...
SNMP est un bon exemple si vous regardez dans le fichier messages [/var/log/messages] vous allez y trouver
...toutes les deux secondes... C'est assez barbant et totalement inutile...
sur ESX 4.1:
cherchez une ligne qui ressemble à:
Retirez le "-a", votre ligne devra ressembler à:
Faites la combinaison de touche Ctrl-O, pressez Enter (pour sauver) et Ctrl-X pour quitter.
Il ne reste plus qu'a re-démarrer votre service snmp:
[ESX] Installer les HP Tools
Si comme moi, vous avez des serveurs HP, vous allez pouvoir installer les HP tools...
Comme toujours on commence par copier le fichier .tgz télécharger chez HP sur le local datastore.
et on le décompresse normalement:
cela va créer une structure /hpmgmt/860/ qu'il faudra navigué et ensuite executer l'installation:
# ./install860vibs.sh --install
HP Insight Manager Agent 8.6.0-11 Installer for VMware ESX
Target System is VMware ESX 4.1.0 build-348481
Server: ProLiant DL380 G5
This script will now attempt to set ESX Host in Maintenance Mode
for IM agents install.
Do you wish to continue? (y/n) y
System is already in Maintenace mode.
Installing HP Insight Manager Agents bulletin [classic-mgmt-solution-860.11.0508]
....OK
/opt/hp/hp-agents-config /vmfs/volumes/System 02/hpmgmt/860
Si vous désirez installer la HP homepage, c'est ici que ca se passe:
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for hpim service (2381) in the firewall [ OK ]
For allowing discovery by HP System Insight Manager, the port (2301)
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for HP System Insight Manager (2301) in the firewall [ OK ]
For the Insight Manager agents to communicate properly with HP Systems Insight
Manager, the snmpd service should be enabled in the firewall.
Maintenant, nous allons configurer le SNMP:
Enabling snmpd service in the firewall [ OK ]
For adding the HP Systems Insight Manager Certificate in SMH, the port [280]
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for SIM Certificate in SMH [280] in the firewall [ OK ]
This configuration script will configure SNMP to integrate with the HP SIM and
the HP System Management Homepage by editting the snmpd.conf file. The HP-SNMP-Agents can also exist in a more secure
SNMP environment (e.g. VACM) that you have previously configured. See the
hp-snmp-agents(4) man page for specific details on how to configure the VACM entries
in the 'snmpd.conf' file. You may press <ctrl+c> now to exit now if needed.
Do you wish to use an existing snmpd.conf (y/n) (Blank is n):
these question will affect the way SNMP behaves. Configuring SNMP could have
security implications on your system. If you are not sure how to answer a
question, you can abort by pressing <Ctrl-c> and no changes will be made to
your SNMP configuration.
Enter the localhost SNMP Read/Write community string
(one word, required, no default):
Re-enter the same input to confirm:
ACCEPTED: inputs match!
Au cas ou vous auriez un doute, ou un trou de mémoire, vous pouvez préciser la valeur par défaut pour l'accès read/write : private
(one word, Blank to skip):
Re-enter the same input to confirm:
ACCEPTED: inputs match!
Vous pouvez préciser la valeur par défaut pour l'accès read : public. Bien sur ces deux valeurs peuvent être choisie selon vos envies ou besoin.
(Blank to skip):
Enter Read Only Authorized Management Station IP or DNS name
(Blank to skip):
Enter default SNMP trap community string
(One word; Blank to skip):
Enter SNMP trap destination IP or DNS name
(One word; Blank to skip):
The system contact is set to
syscontact Root <root@localhost> (configure /etc/snmp/snmp.local.conf)
Do you wish to change it (y/n) (Blank is n):
The system location is set to
syslocation Unknown (edit /etc/snmp/snmpd.conf)
Do you wish to change it (y/n) (Blank is n):
==============================================================================
NOTE: New snmpd.conf entries were added to the top of /etc/snmp/snmpd.conf
==============================================================================
snmpd is started
[ OK ]
Stopping System Management Homepage: [ OK ]
Starting HP Insight Manager agents: [ OK ]
Starting System Management Homepage: [ OK ]
Stopping SNMP stack:
Stopping snmpd: [ OK ]
Starting SNMP stack:
Starting snmpd: [ OK ]
**********************************************************
* System Management Homepage installed successfully with *
* default configuration values. To change the default *
* configuration values, type the following command at *
* the root prompt: *
* *
* /opt/hp/hpsmh/sbin/smhconfig *
* *
**********************************************************
Please read the License Agreement for this software at
/opt/hp/hp-health/hp-health.license
By not removing this package, you are accepting the terms
of the "License for HP Value Added Software".
HP Insight Manager agents have been configured successfully!
/vmfs/volumes/System 02/hpmgmt/860
HP SNMP agents are installed and configured
Reboot the system to make the changes effective.
C'est ici qu'il faut passer par la reconfiguration du snmpd... sinon votre messages logs va etre flooder... (voir ce lien)
Vous pouvez également faire un clean de votre datastore:
# rm -f hpmgmt-8.6.0-vmware4x.tgz
[ESX] Mettre a jour vers 4.1 via ssh
Oui je sais il existe un outils tout fait... Mais j'avoue que là, j'hésite encore a m'en servir... J'ai en effet du re-installer complètement un host suite à l'usage (foireux) de cet outils, donc, je ne suis pas convaincu que ce soit la bonne idée...
Téléchargez les fichiers suivant sur un volume local de votre ESX:
upgrade-from-ESX4.0-to-4.1.0-0.0.260247-release.zip
Dans mon cas je les ai copié sur le volume VMFS"System 01"
Si votre serveur n'est pas encore en mode maintenance:
vous pouvez aussi le faire via le client VSphere.
pour accéder au volume VMFS "System 01", vous devrez suivre le chemin suivant:
/vmfs/volumes/System\ 01/
notez la présence d'un '\' en plein milieu, ce caractère permet de placer un espace dans le chemin sans que le système y voit un séparateur...
lancez la pre-upgrade et laissez faire:
Unpacking vmware-esx-esxupdate-4.1.0-0.0.260247.i386.vib ########## [100%]
Unpacking vmware-esx-uwlibs-4.1.0-0.0.260247.i386.vib ########## [100%]
Unpacking glibc-common-2.5-34.2926.vmw.x86_64.vib ########## [100%]
Unpacking glibc-2.5-34.2926.vmw.x86_64.vib ########## [100%]
Unpacking glibc-2.5-34.2926.vmw.i686.vib ########## [100%]
Installing glibc-common ########## [100%]
Installing glibc ########## [100%]
Installing glibc ########## [100%]
Installing vmware-esx-uwlibs ########## [100%]
Installing vmware-esx-esxupdate ########## [100%]
Cleaning up vmware-esx-esxupdate ########## [100%]
Cleaning up vmware-esx-uwlibs ########## [100%]
Cleaning up glibc-common ########## [100%]
Cleaning up glibc ########## [100%]
Cleaning up glibc ########## [100%]
Cette opération prendra un peu de temps, mais nettement moins que la suivante:
Host was not updated, no changes required.
Skipping bulletin ESX410-GA-esxupdate; it is installed or obsoleted.
Unpacking rpm_vmware-esx-likewise-ad-provider_4.1.0-0.0.2602.. ########## [100%]
Unpacking rpm_vmware-esx-srvrmgmt_4.1.0-0.0.260247@i386 ########## [100%]
Unpacking rpm_vmware-esx-drivers-char-tpm-tis_400.0.0.1.1-1v.. ########## [100%]
:
:
Cleaning up vmware-esx-nmp ########## [100%]
Cleaning up vmware-esx-drivers-net-tg3 ########## [100%]
Cleaning up nss_ldap ########## [100%]
Running [/usr/sbin/cim-install.sh]...
ok.
Running [/usr/sbin/vmkmod-install.sh]...
ok.
Running [esxcfg-boot -b]...
ok.
The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Ensuite, un simple reboot pour finaliser l'installation
Et voila, votre ESX doit etre en version 4.1:
VMware ESX 4.1 (Kandinsky)
[ESX] Réduire la taille d'un vmdk
Dans mon métier, on doit parfois économiser de la place, mais sans rien effacer... Avant [VMWare] c'était impossible, maintenant, il existe un moyen... il s'agit du thin provisioning, en opposition au thick provisioning.
Thin ou Thick
Pour faire court, il est conseillé en VMWare de toujours alouer ses disques en mode thick (ce mode a l'avantage de faire des disques performants et rapides, mais a le désavantage (relatif) d'allouer toute la place demandée à la création du disque).
C'est aussi ce type de disque qui est créé par les outils P2V.
Alors oui, l'on peut débattre sur les raisons qui vous poussent à transformer des disques thick en thin provisioning, mais sur un ESXi de labo les performances sont rarement la priorité, et souvent vous n'avez pas la possibilité de "migrer" la machine d'un DataStore a un autre en changeant le type de provisioning.
J'ai dû, sur un ESXi qui supporte le réseau de formation, gagner de la place. En gros, j'avais besoin de récuper au minimim 50 GB) et il se trouve que sur mon seul datastore du labo, j'avais deux disques vmdk de 50 GB en mode thick (soit une allocation de 100GB), alors que l'un n'avait que 10 GB réellement utilisé, l'autre occupait 25 GB). Malheureusement pour moi, il ne me restait que 15 GB de libre sur le Datastore...
Marche a suivre
Soyez conscient que pour ces manœuvres, votre serveur ne sera pas disponible a vos utilisateurs.
Voyez la NOTE plus bas si vous devez maintenir un accès au serveur (ou que cette procédure prend trop de temps pour une fenêtre offline).
- Trouvez les bons disques
Vous devez parcourir vos Disques Virtuels dans vos machines pour voir le quel est le moins rempli.
Videz la poubelle, voyez si tout ce qui est sur le disque est réelement nécessaire (par exemple, j'avais 5 GB de temporaires et de fichiers d'installation inutile sur sur ce disque).
Arrêtez les services inutiles par exemple SQL, antivirus, etc... (Voir la NOTE)
 N'oubliez pas aussi de passer par la case défragmentation avant de continuer, cela peut sembler logique, mais j'avoue ne pas y avoir penser au début, et avoir perdu une bonne heure pour un résultat médiocre.
N'oubliez pas aussi de passer par la case défragmentation avant de continuer, cela peut sembler logique, mais j'avoue ne pas y avoir penser au début, et avoir perdu une bonne heure pour un résultat médiocre.

- Préparez le disque en utilisant les outils VMWare dans la machine Virtuel
Comme vous le savez surement, quand vous effacer un fichier, Windows n'efface pas réellement les données: le descripteur du fichier (son nom, le créateur, les dates connues [création, modification, accès], l'emplacement physique sur le disque, etc) est placé dans la poubelle, l'opération de vider la poubelle, efface ces descripteurs et marque les block de données comme libre... Windows sera libre de faire usage "au besoin" de ces blocks plus tard (bien plus tard en faite).
Donc l'outil VMWare va se charger de "mettre a zéro" ces blocks; en créant de gros fichiers de 2 GB nommé "wiper0", "wiper1", ... Ces fichiers vont permettre a l'ESX d'identifier les blocks comme étant réellement inutilisés.
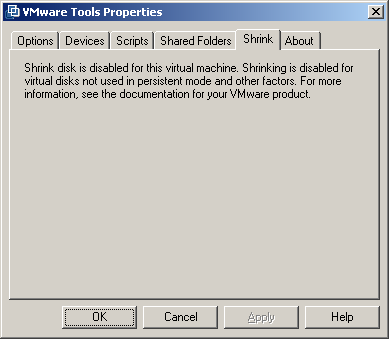
Si comme moi vous rencontrez ce type de message, dites vous que vous etes dans le bon, c'est juste que VMWare ne fait pas de shrink sur un disque en mode thin (c'est idiot mais bon)...
Normalement, votre disque est de base en thick, donc cette option sera active pour vous. Une fois que l'outil aura fait son œuvre, arrêter la machine Virtuelle.
NOTE Normalement vous devez avoir un downtime pour faire ces opérations "a l"aise"; mais il existe un moyen pour ne pas couper le serveur durant ces manœuvres, et donc maintenir l'accès; je n'ai pas tester cette méthode, donc je vous recommande la plus extrême prudence:
Arriver a ce point, vous devriez arreter votre serveur, mais vous pouvez aussi créer un snapshot du disque en question; tous les accès en écriture sur ce disque seront fait sur le snapshot et non sur le disque d'origine.
A la fin du clone - remplacement, il suffira d'effacer tout les snapshots de la machine; cela aura pour effet d'ajouter dans votre image finale, tout les changements effectués depuis le snapshot et de libérer ainsi la précieuse place.
- Ouvrez une session "root" via SSH sur un host ESX qui a accès au datastore
Rendez-vous en ligne de commande dans le bon dossier de stockage du serveur:
Dans cet exemple, j'utilise datastore1 comme volume VMFS et srv-mordred comme nom de machine virtuelle.
Avec une simple commande ls -l vous obtiendrez tout le contenu du dossier; mais en précisant un peu, il y a moyen de faire beaucoup mieux:
-rw------- 1 root root 502 Feb 3 10:38 srv-mordred.vmdk
-rw------- 1 root root 505 Feb 3 10:39 srv-mordred_1.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1-flat.vmdk
-rw------- 1 root root 32212254720 Feb 3 10:41 srv-mordred-flat.vmdk
L'on constate que les vmdk se répartissent en deux type des petits fichiers (moins de 5 KB, ici 502 et 506 bytes) et de très gros fichiers où est ajouté "-flat" au nom du disque, il se peut que vous ayez des fichiers avec "-XXXXX" ajouté dans le nom, ce sont les fichiers de snapshot, "-XXXXX-delta" contiendront donc logiquement les données de différence par rapport au disque d'origine.
NOTE: Vous pourrez noter que la console ne voit pas la taille réellement occupée par le disque, mais bien la taille maximum allouée a la création du disque (ici un disque de 30 GB et un de 50 GB), même si vous avez créer un disque "thin"; pour avoir cette taille réel, il vous faut allez dans le datastore browser.
- Créez un clone 'Thin' de votre disque
C'est ici que tout se joue, l'outil qui va tout faire pour vous (ou presque): "vmkfstools", ordonnons lui de faire un clone thin de votre disque:
l'option -i (input) spécifie le fichier source, l'option -d (destination) attends deux paramètres, le format du disque et son nom; dans ce cas ci,nous précision thin et le nom sera clair lui aussi.
Cloning disk 'srv-mordred_thin_1.vmdk'...
Clone: 100% done.
Une fois le clone fini, un petit 'ls' pour vérifier la présence du nouveau couple de fichiers:
-rw------- 1 root root 502 Feb 3 10:38 srv-mordred.vmdk
-rw------- 1 root root 505 Feb 3 10:39 srv-mordred_1.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1-flat.vmdk
-rw------- 1 root root 510 Feb 3 10:39 srv-mordred_1_thin.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1_thin-flat.vmdk
-rw------- 1 root root 32212254720 Feb 3 10:41 srv-mordred-flat.vmdk
Vous pourriez être surpris que la taille du nouveau fichier flat est exactement la même que l'original thick; c'est du au fait que la console "voit" la taille des disques et non l'espace réellement occupé sur le stockage. Vous devrez allez dans le datastore browser pour y voir l'espace occupé.
- Remplacer le disque 'thick' avec le clone 'thin'
vous pouvez sans crainte effacer l'ancien 'thick' disque par le clone que vous venez de créer :
N'oubliez pas d'effacer le fichier de description "srv-mordred_1_thin.vmdk" qui n'a plus de raison d'être.
Vous pouvez bien sur toujours éditer le fichier de description pour y ajouter une ligne:
afin d'expliquer correctement a VSphere que c'est un disque thin et non thick.
EDIT: Connaitre la taille utilisée réelement et virtuellement
L'allocation de la taille se fait via le vsphere... Vous y verez la taille effectivement restante... a coté de la taille déjà "allouée"...
vous allez dans votre dossier /vmfs/volumes/VOLUMES
il existe une commande 'du -h' qui vous affichera l'usage disque réel de vos dossiers (pas l'alloué).
Un parametrage un peu barbare 'du --apparent-size -h' vous affichera l'usage disque virtuel (y compris les VMDK qui pointent vers des RDM)
[ESX] VMWare: théorie des stockages
Quant on travail avec VMWare on a parfois tendance a oublier les bases... Voila une piqûre de rappel plus que nécéssaire sur comment on stock des données sur un disque dur... et comment VMWare "émule" cela...
La machine Physique
Quand une application sur une machine physique veut écrire quelque chose sur un disque local, l'OS de la machine émet une requête d'écriture, cette requête va être traiter par le contrôleur de disques auquel est attaché le disque visé. Le HBA ou Contrôleur de Disque se charge de la gestion des disques (RAID, redondance, etc...)

La machine Virtuelle (VM)
Il en va de même pour une VM à la différence que les ordres traités par "contrôleur de disque" de la VM, vont être interceptés et redirigés vers le fichier VMDK qui "contient" les données du disque virtuel. Le serveur host VMWare va résoudre le chemin vers le datastore visé, et ce quelque soit la nature profonde du stockage. Sur un host avec stockage local, il s'agit d'initier un dialogue avec le HBA qui contrôle le disque dur en question et d'émettre une commande d'écriture d'un bloc donné à un endroit donné sur le disque.
![]()
Augmentation des Volumes et des disques
Quand le nombre de disques de stockage augmentent, et que nous débordons la capacité maximale du contrôleur SCSI, nous passons d'une version "direct attached" à une "mise en réseau" des disques, évidement le SCSI n'est pas capable directement de débordé son nombre de disque maximum, il faut passer par un appareil qui fera la jonction entre un grand nombre de disques physiques (plusieurs dizaines) et les serveurs qui ne peuvent voir qu'un faible nombre de disques (moins de 20).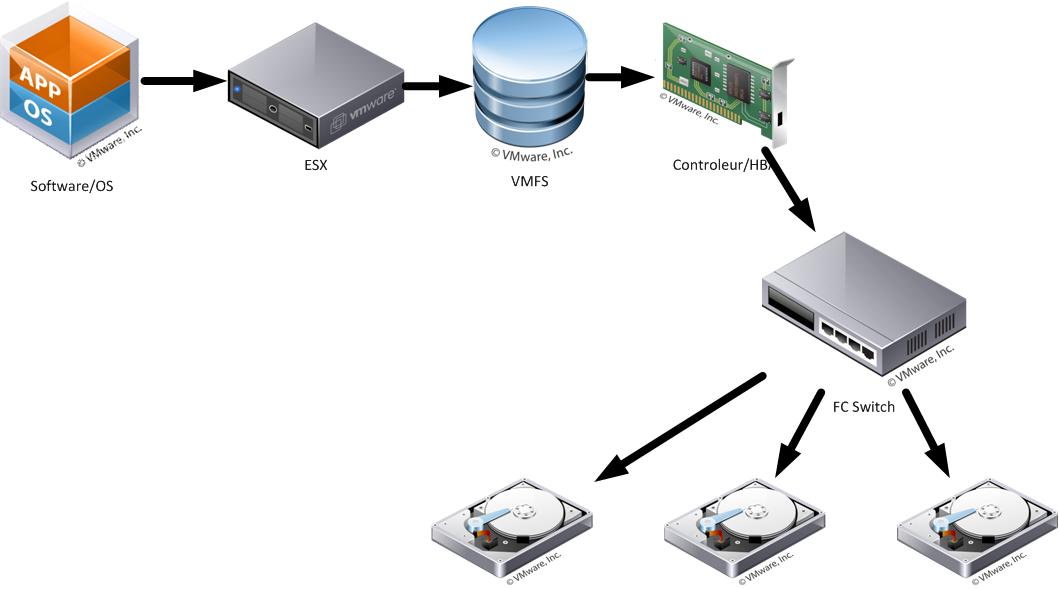
Les SANs
C'est l'idée de base des SAN qui offraient un grand nombre de disques montés et présentés comme un seul (ou quelques) disque(s) aux serveurs ESX.
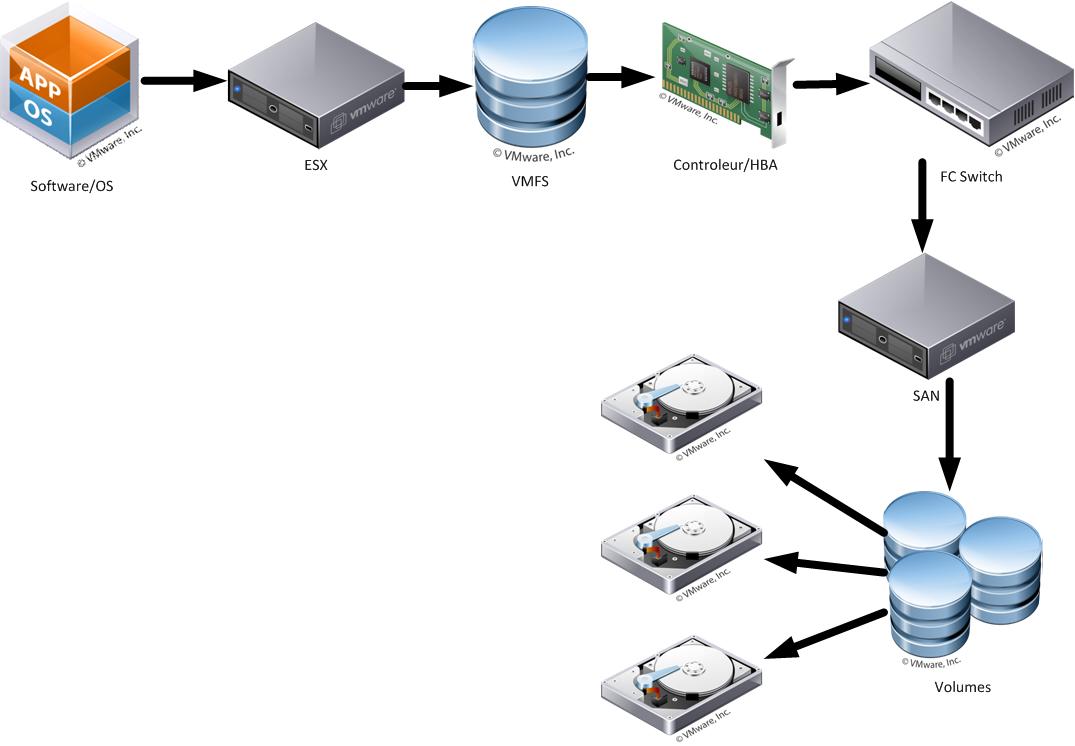
Cette suite d'événements parait évidente et simple, surtout avec des technologies éprouvées comme le FibreChannel (FC), mais n'oublions pas que VMWare écrit au final dans un fichier VMDK sur un filesystem VMFS, et que dans le cas d'un système de stockage distant a technique est la même que pour un disque local, sauf que les contrôleurs HBA doivent initier un dialogue avec un appareil distant, et que ce dialogue peut passer via divers appareils (switches fabric, controlleurs de SAN, etc) et dans ce cas déjà, beaucoup de problèmes externes peuvent se présenter.
Les NASs
Si au lieu d'utiliser un protocole "bloc", comme le FiberChannel, on doit écrire sur un NAS en iSCSI ou en NFS, les NAS n'écrivent pas directement sur des volumes, mais écrivent dans des fichiers locaux, au travers de l'OS du NAS:
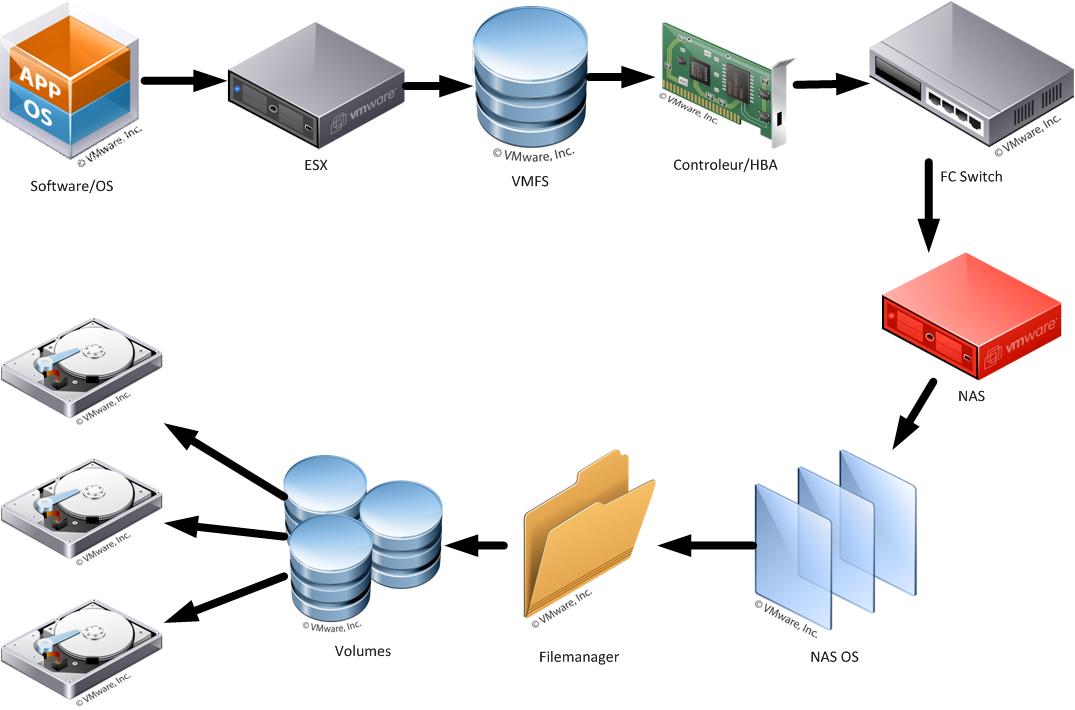
Ce système de fichiers NAS contient outre les données des fichiers également des métadonnées. Dans de nombreux cas, il est très important pour la stabilité du système que les métadonnées soient mise à jour de manière prudente et réfléchie, car si elle n'est pas, et il y a un réel risque de perte de données, en cas d'accident ou de panne de courant, qui pourrait rendre le système de fichiers instable, inutilisable, et même irrécupérable.
La Synchronisation
Quelque soit le type de stocakge (local, DirectAttached, NAS, SAN) il est important pour VMWare de s'assurer que toutes écritures a été faite correctement et réellement, donc en bon élèves, un ESX attendra la confirmation d'écriture avant de passer (réellement) à autre chose.
Le signal de synchronisation fournit a l'ESX l'assurance que les données qu'il a écrit sont écrites sur un disque et non "en transit". Ce type de signal dans un protocole "hardware" comme le FibreChannel ou le SCSI est assez facile a obtenir (puisque le contrôleur (ou le SAN) est responsable directement de la gestion des disques), mais plus délicats dans le cas d'un NAS du fait de la couche "software" qui ne sais pas toujours si les disques ont un "cache" d'écriture ou non.
ESX et les blocs de données
Un host VMWare considère toutes demandes d'écritures disques venant d'une VM comme "importantes" et prendra donc TOUTES les garanties pour l'écriture de celles-ci. Ce qui signifie qu'il attendra la réponse du système de stockage. Sur un SAN (ou tout autre système "bloc") cette réponse sera souvent immédiate (ou presque) mais sur un NAS, qui pour augmenter les performances, utilise souvent des caches et écrit sur les disques de manière asynchrone, cela peut prendre du temps.
Alors voilà le problème, ESX représente le disque dur de votre machine virtuelle dans un fichier VMDK. Cependant, il n'a vraiment aucune idée de ce que VM tente d'écrire sur le disque, et donc considère que toute écriture est précieuse. En d'autres termes, VMware écrit tout avec une demande de confirmation de synchronisation. Cela peut entraîner des ralentissements importants.
Sur un serveur avec stockage local, la solution typique à ce problème est d'utiliser un contrôleur RAID équipé de write back cache et d'une batterie de secours.
La même chose se produit sur des périphériques réseaux, VMware exige que toutes écritures soit faite sur un stockage stable,
Maintenant, il est important de comprendre que VMware veut être prudent avec vos données. Disons que votre VM met à jour certaines métadonnées du système de fichiers, par exemple, la table de blocs libres, car un certains nombres de fichiers ont été crées sur la VM.
- La VM écrit une mise à jour qui indique quels blocs ont été utilisés.
- ESXi envoie cette mise à jour vers le système de stockage NAS / SAN. Supposons que l’écriture est différée (pour des raisons de performances) et qu’à ce moment précis, une panne de courant (non secourue) survient.
Après redémarrage, le NAS montrera ces blocs comme libre et vide, la VM pourra écrire sur ces block (et donc remplacer le contenu des fichiers crées juste avant le crash).
Donc, la solution de VMware est de s'assurer que les écritures sont signalées comme synchronisé et de confier le problème du sous-système de stockage.
Sync or not Sync ?
Si dans les périphériques "blocs" (comme le SCSI ou le FiberChannel) la question ne se pose pas, elle se pose largement pour les périphériques "réseaux" et les protocoles IP.
En général, dans un protocole réseaux, vous avez le choix d’activé la synchronisation ou non, c'est souvent une question de cout/performances/risques qui vous permettra de décider.
- NFS, par défaut, activera la synchronisation en écriture à la demande des ESX. C'est pourquoi il est lent. Vous pouvez améliorer les performances avec un cache Front en SSD.
- iSCSI, par défaut, n’a pas synchronisation. En tant que tel, il apparaît souvent comme beaucoup plus rapide, et donc un bien meilleur choix que NFS, cependant, attention là aussi aux pertes de données. On peut activer la synchronisation sur les données iSCSI, mais dès lors les performances seront en baise.
[Workstation] Monter des VMDK sous Windows 7 64bits (même Ext2 et 3)
Rhhaaaaa, la version Workstation 9 ne supporte que des cartes réseaux à 100Mbps, et pour transférer de gros volumes c'est LENT! Pas de panique, il existe une solution simple, monter le volume sur l'OS host (ici Windows 7 64bits).
C'est simple pour des disques VMDK en NTFS ou en FAT (32), mais pour les disques en Ext2/3 vous pouvez allez vous brosser... mais j'ai la solution.
Monter un volume (NTFS/FAT(32))
Pour monter un Volume VMDK sur le host (Windows) c'est assez simple:
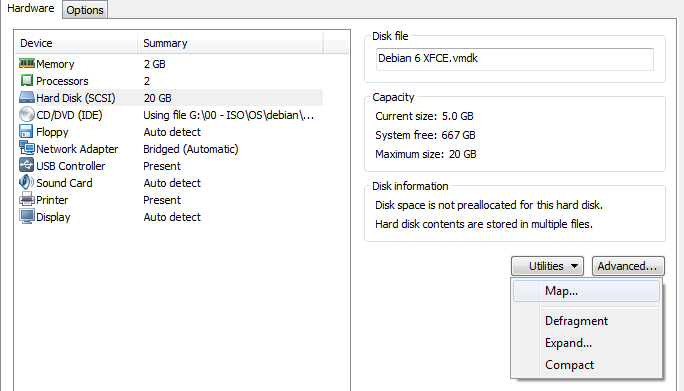
Puis de remplir les paramêtres:
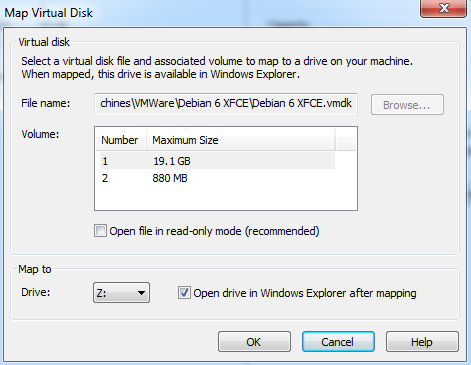
Pour du NTFS/FAT aucun soucis, pour du EXT2/3, vous aurez Windows qui vous demandera a formater la partition... horreur :D
La Solution
Il suffit d'installer le drivers qui va bien: ext2fsd
Une fois ce drivers installer, votre partition sera visible comme une partition Windows classique dans votre explorer...
Tutoriaux: Où comment je (vous) apprends des trucs...
Voilà, je voulais réaliser un projet qui me tiens a coeur depuis... des années, quelques choses qui remonte loin dans mes années d'études... mais voilà ni le temps ni les connaissances n'étaient au rendez-vous... Ce projet porte le nom d'Aurora... je vous en parlerais au fil des articles...
Millieu des années 90, c'est le temps de développer les deux parties (clients et serveurs) qui m'a arreter, je connaissais la téhorie, j'avais de bon exemples et quelques test pas mal torchés.mais il faillait toujours créer les deux parties du puzzle et de solide connaissance en C/C++ et en directx naissant...
Ensuite les serveurs ont commencés a devenir accessibles et intelligent, des languages de programmation sont apparu coté serveur aussi ASP; je ne croyais pas trop au JAVA (a tord ou a raison, ce n'est pas le débat).
aujourd'hui la puissance des machines est tel que même en Javascript HTML5 on fait des truc de oufs, sans se sortir la main du slip...
mais cela demande une solide connaissance comme toujours; je vous propose de me suivre dans mes découvertes de technologie; j'ai de bonnes bases en logique, d'assez bonnes bases en php4/5, HTML et SQL, et des notions de CSS.
mon objectif est complexe:
- Réaliser un moteur Isométrique sur un navigateur
- connecter ce moteur a une base de données centrale en temps réel
- rendre cela "beau"
Vous l'aurez compris, c'est un truc "lourd"...
j'écrirais des articles en forme de pense-bête, ou simplement pour vous donner des trucs et astuces suivants mes recherches.
pour vous situer, j'ai développé au fil du temps une sorte de framework, qui à la longue, est devenu une vrai usine a gaz; et donc je profiterais de mes recherches sur le projet Aurora pour vous donner un apperçu sur les améliorations/optimisations/nettoyage du code de mon framework Version 1 vers une Version 2 qui je l'espere sera plus rapide et plus facile a gérer.
Tutoriaux: serveur(s) de développement
Avant de commencer le vif du sujet; il est bon de choisir sa plateforme de developpement... pour moi j'ai testé plusieurs choses, et j'ai donc émis le cahier ci-dessous.
Cahier de charges
- Le serveur doit être porteur et fonctionner sur une plateforme où j'ai un gros accès comme sur une plateforme ou seul le PHP m'est accessible
- Peu couteux
- Simple a mettre en place et a gérer
- Langage PHP/SQL pour le serveur
- Pas de solution propre a un OS
Apache: http://www.apache.org
PHP: http://www.php.org
MySql: http://www.mysql.com
Les choix
N'ayant (et ne voulant) pas de mac, je ne viserais que deux OS: Windows et Linux
Le serveur debian/apache2/mysql
En gros il s'agit du serveur "définitif" du projet...
C'est l'un des moyens que j'ai conservé pour le developpement. On peut aisément installer une console graphique dessus, mais je ne vous le recommande pas.
Pour
- Plateforme "définitive", donc ce qui marche dessus marchera quand le projet sera en ligne...
- Stable et performant
- Cout en licenses innexistant
- Pas lié a un seul projet/site
Contre
- Maintenance complexe si l'on ne connait pas
- Demande de suivre certaines procédures pour arriver à un résultat
Liens et conseils
Debian: http://www.debian.org
pour installer les serveurs:
Le Serveur Windows/apache2/Mysql
J'ai passé sous silence le serveur Windows/IIS, car cela ne couvrait pas mon cahier de charge...
Il existe deux choix possibles: EasyPHP et WAMP.
EasyPHP
Pendant des années je me suis basé sur EasyPHP pour sa facilité et sa souplesse, mais lors du passage sur serveur de production, j'ai eut beaucoup de surprises et de changement a faire. La faute aux choix et options "de base" de cette solution qui se voulant facile vous active pas mal de librairie et d'options de base.
Pour
- Facile
- l'édition des sources se fait naturellement
- ajout de "modules" d'un simple clic de souris
Contre
- Des choix d'options pour faciliter la gestion parfois malheureux
- les portages Linux -> Wndows pas toujours en 64bits
Liens et conseils
Easyphp: http://www.easyphp.org
WAMP
Pour l'instant, c'est LE choix a faire si vous développez sous windows.
Pour
- Version 32 et 64bits disponibles.
- Grand choix de version de MySQL et de PHP dans les téléchargement
- Support (téhorique) de plusieurs versions sur une même instances (il faut quand même sélectionner quelle est LA version est active)
- Debugger intégré et un bon rapport d'erreur (parfois un peu trop complet :))
- Apache PHP et MySQL avec une configuration "out of the box" qui demande parfois des adaptations
Contre
- Un peu technique pour débuter
Liens et conseils
Tutoriaux: Le CSS
Introduction
Je trouve ca lourd (surtout aujourd'hui) de devoir parcourir un (voir plusieurs) fichier(s) CSS pour modifier la couleur d'un élément; voir parfois de dizaines car vous trouvez que je vert ne convient pas aussi bien qu'un bleu pour TOUT les éléments de votre page... et donc vous devez rechercher dans vos CSS toutes les #15FF12; mais aussi les #18FC11; et puis vous trouvez a la fin un #182500; qui vous pourris bien la vie...
heureusement il y a LessCSS...
Le tutorial est fait pour la version 1.3.3, mais le code ci-dessous est facilement adaptable à d'autre versions.
De plus LessCSS *peut* vous aider a faire du responsive design (1)...
Mais qu'est ce que c'est...
En deux mot: un préprocesseur CSS. LessCSS est au CSS ce que le PHP est à l'HTML...
Qui n'a jamais rêvé de définir une fois pour toute SA couleur de base, et ensuite de faire des déclinaisons matématique en CSS...
et bien LessCSS est là pour ça (entre autre)...
Vous allez me dire oui, mais mon code est déjà bien avancé et je ne veux pas tout modifier, ben c'est pas très compliqué à utiliser... Même sur des applications bien avancées en développement.
Vous avez deux techniques; le précompilé ou l'interprété à la volée...
Pour le développement je vous conseille le second, pour la production le compilé c'est bien aussi.
Le précompilé ?
Oui, vous écrivez vos LessCSS, puis via une appli Windows/linux voir même en ligne, vous compilé vos code Less en CSS, et vous n'avez plus qu'a modifier la référence CSS (ou a remplacer votre CSS de base par le résultat compilé) et hop le tour est joué.
en ligne voici quelques outils:
http://www.dopefly.com/less-converter/less-converter.html
A la Volée
C'est la solution que j'utilise aujourd'hui
Dans mon framework personnel (Version 1), j'ai un fichier "header.php" qui contient le début du code d'une page classique (en gros les balises <HTML> <HEAD>, </HEAD> et <BODY>).
voici un extrait de mon <head>:
<title>Test CSS</title>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<script src="<? echo _js_.'jquery.min.js'; ?>"></script>
<script src="<? echo _js_.'jquery-ui.min.js'; ?>"></script>
<script src="<? echo _js_.'tabber.js'; ?>"></script>
<script src="<? echo _tiny_mce_ ?>jscripts/tiny_mce/tiny_mce.js"></script >
<link href="<? echo _css_.'main.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'login.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'gui.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'advgui.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'menu.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'header.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'footer.css'; ?>" rel="stylesheet" type="text/css">
<link href="<? echo _css_.'common.css'; ?>" rel="stylesheet" type="text/css">
</HEAD>
Je reviendrais sur le chargement des javascript plus tards, ce qui m'interesse se situe dans la partie CSS. j'ai beaucoup de CSS, car mon Framework a évolué avec le temps, de façon anarchique.
Ce fichier php initalise aussi quelques paramêtres vitaux, et contient l'inclusion des CSS natifs de tout le projet (oui TOUT les CSS, donc parfois un joyeux bordel).
J'ai donc adapté ce php pour utiliser LessCSS;
$page[css] = 'main';
Puis dans la section <HEAD> </HEAD> elle charge le CSS demandé:
Et enfin le script less:
<title>Test CSS/LESS</title>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<link rel="stylesheet/less" href="css/main.less" type="text/css"/>
<script src="js/less-1.3.3.min.js" type="text/javascript"></script>
</head>
voici les sources .less de cet exemple
common.less
CSS (c) 2003-2013 Nox-Rhea
*/
//
// basic Color Definition
//
@nice-blue: #5B83AD;
@light-blue: (@nice-blue + #111);
@dark-blue: (@nice-blue - #111);
.rounded-corners (@radius: 5px, @borderwidth: 1px, @bordercolor: #000)
{
-webkit-border-radius: @radius;
-moz-border-radius: @radius;
-ms-border-radius: @radius;
-o-border-radius: @radius;
border-radius: @radius;
border-width: @borderwidth;
border-color: @bordercolor;
border-style: solid;
}
main.less
@import "menu.css";
#login
{
border-width: 1px;
color: @dark-blue;
.rounded-corners(5px,1px,@light-blue);
margin: 5px 5px 5px 5px;
float: left;
width: 49%;
}
pour résumé, nous avons deux fichiers inclus (via la commande @import) qui contienent toutes les définitions de base de notre css (common.less et menu.css); puis un fichier main.less qui contient les définitions de la page (sur base du fichier common.less), il est intéressant de noté que les fichiers .css (et qui ne contiennent pas de définition LessCSS, sont importés tel quel dans le fichier final; en version javascript les commentaires sont "oubliés" mais en version compilée, les commentaires CSS sont conservés.
Et le résultat dans votre page
#login {
border-color: #6C94BE;
border-radius: 5px 5px 5px 5px;
border-style: solid;
border-width: 1px;
color: #4A729C;
float: left;
margin: 5px;
width: 49%;
}
Vous pouvez voir qu'il y a des optimisations (margin: par exemple) mais surtout que les couleurs sont calculées a partir de la couleur de base "@nice-blue". Si vous référencez une variables qui n'existe pas (plus) vous aurez un message d'erreur:
Simple non ?
(1) Je dis *peut* car je n'ai pas testé le truc à l'heure où j'écris ces lignes... (Il faut impérativement utiliser la version javascript de LessCSS pour que cela fonctionne...)
Tutoriaux: la 3D, l'ISOmetrique et un écran...
Précisions
Avant de commencer, et surtout de me faire incendier par les puristes, je tiens a préciser quelques points et à rappeler certaines notions de base, même si dans la suite de l'article, je dis le contraire ou que je suis imprécis:
- Il n'existe pas de 3D... même les derniers jeux a la modes, font ce que l'on appelle une "projection" 3D vers l'écran.
- la 3D isométrique est un abus de langage, car en réalité c'est de la 2D, affichée différemment, ce n'est donc PAS de la 3D, il faudrait parler de projection isométrique, d'ailleurs on parle bien souvent de 2.5D.
Voilà une fois ces remarques posées, nous pouvons passer à la suite.
La 3D Isométrique, rien de mieux pour un browser web...
A la base je comptais faire un "gros" article et en rédigeant celui-ci, je me suis dit; c'est assez indigeste... donc cela sera plutot une série, et comme je suis assez mauvais en introduction, je vais mettre ici quelques sites qui m'ont servi de référence:
- glacialflame, un projet de 3DIsométrique en HTML5, qui a disparu aujourd'hui, le site n'existe plus, mais archive.org est là, de bonnes bases en sommes...
Tutoriaux: Isométrique et 3D...
Introduction
Pourquoi cet article
J'ai écris cet article, car malgré des recherches avancées, je n'arrive pas a trouvé de source complète sur le sujet ni vraiment de mise en pratique de la théorie, certes il existe des plug-ins ou du code tout fait, mais rien qui satisfasse réellement ma soif de connaissances et mon envie de comprendre.
L'une des raisons à ce manque d'informations est sans doute que la 3d isométrique à été supplantée dans les jeux par la "3D pure".
Dans le cadre d'un jeu WEB, les développeurs préfèrent la 2D pure, c'est plus simple à gérer, et beaucoup plus rapide a calculer; c'est donc une technologie très rentable;
Seulement, je trouve que c'est moche, et que la 3D isométrique est le meilleur compromis.
Qu'est ce que la 3D isométrique
La 3D isométrique est un moyen de rendre l'effet de perspective et de profondeur en utilisant des éléments en 2D. Appliquée à une carte composée de cases, cette technique donne un rendu saisissant mais pour bien la comprendre, il est nécessaire de réfléchir à ses implications mathématiques. L'objet de ce tutoriel est d'expliquer pas à pas la théorie de la 3D isométrique lorsqu'elle est utilisée sur un site WEB. Les paragraphes qui suivent contiennent de nombreuses références mathématiques mais peu de code.
Les bases
Les jeux de "cartes"
Pour faire un bon jeu d'aventure ou un jeu de role, rien ne vaut un monde vaste, et qui dit monde, dit carte(s); le plus simple pour faire une carte, c'est de prendre une feuille de papier quadrillé, et de dessiner dessus...
En informatique, c'est pareil...

c'est donc un univers 2D qui est représenté, vu de haut; c'est facile a faire avec un ordinateur, une case de la carte s'affiche sans modification sur l'écran (tout au plus faut il gérer les très grandes cartes qui dépassent de l'écran. Mais il faut avoué que cela manque d'entrain, et aussi belles soient les cases, cela reste une carte et non un monde...
Tiles et changement de vue...
Oui, je vais parler de "tiles" et non de "tuilles" car je n'aime pas la fancisation dans n'importe quel sens... donc je parle de tile et de tileset 
Avant tout, je rappelle la "procédure" pour créer des tiles isométriques.
Par le passé, les logiciels de dessin utilisaient comme référence le pixel d'écran; et les graphistes devenaient souvent soit des Dieux du positionnement "au pixel près" soit adepte du Zoom; l'un des logiciels les plus connu sur Amiga était le Deluxe Paint (qui fut d'ailleurs porté sur PC)et RIEN n'a (a mes yeux) remplacer ce merveilleux logiciel pour ce type de dessins.
Pour créer une vue isométrique utilisable sur ordinateur, on applique une rotation de 45° vers la droite, puis un "écrasement" de 50% en hauteur.
Dans le temps, il fallait une sacrée dose de patience pour réaliser ces "tiles" afin qu'elles s'associent l'une à l'autre par les cotés.
Aujourd'hui, il existe de très bon logiciels qui réalise ces oppérations pour vous, je citerais le World Creator de www.inet2inet.com. Ce logiciel n'est peut-être pas le plus efficace, mais il est certainement le plus précis.
On se retrouve donc avec des images rectangulaires contenant des formes tordues, d'où la difficulté de les coller les unes aux autres. Je rappelle que si l'on considère la carte comme un plan orthonormé, l'origine est en haut à gauche.
Avec ces formes "en losange", si on est un peu codeur, on comprend très vite que cette vue 2.5D est un peu une sorte d'enfer, car il faut avancer dans deux dimensions x/y alors que l'on dessine un ligne (ou une colonne) de notre carte.
Affichage
Pour des raisons de simplicité, je melangerais dans ce tutorial HTML, CSS et JavaScript; il est évident qu'il ne faut surtout pas faire comme cela, mais bien séparer les trois (quand c'est possible évidement)
Là, où en simple 2D, vous auriez imbriqué deux boucle for(); et vous auriez multiplier les indices de case par la taille de l'image a affiché.
Admettons que nos tiles fasse 64x64 pixels, voici comment vous auriez affiché:
for(x=0;x<map_sizex;x++)
echo "<div id=\"case_".y."_".x."\" style=\"position: absolute; left: ".($x*64)."px; top: ".($y*64)."px;
background-image: url('".$impath."floor-".$im.".png');width: 64px;height: 64px;\"></div>";
en isométrique, cela ne fonctionnera pas... car il faut "imbriquer" les losanges... mais pas de panique, voici la marche a suivre:
for($x=0;$x<$map_sizex;$x++)
{
$px = ($x-$y)*(64/2);
$py = (($x+$y)/2)*(64/2);
echo "<div id=\"sol_".$y."_".$x."\" style=\"position: absolute; left: ".$px."px; top: ".$py."px; width: 64px; height: 64px;
background-image: url('".$impath."floor-".$im.".png');\"></div>";
}
Et voilaaaa... vous avez un sol en 3D isométrique.
Optimisation ?
Là, je vous vois crier au scandale. Oui, j'affiche une fois toute la map, elle va dépasser de l'écran, ca va être moche etc...
En fait non, c'est assez simple d'éviter de montrer toute la carte; j'affiche la carte dans un DIV qui est lui même dans un DIV view; je centre la vue au début:
$maps_sizex = 10;
$centerx = ($maps_sizex/2);
$centery = ($maps_sizey/2);
$positionx = (($centerx-$centery)*(64/2));
$positiony = -((($centerx+$centery)/2)*(32/2))+(640/2);
echo "
<div id=\"view\" tabindex=\"0\" style=\"width:768px; eight:640px; overflow:hidden;\">
<div id=\"view\" style=\"position:absolute; top: $positiony; left:$positionx;\">";
Sécurité - protection de la vie privée
La Sécurtité, la protection de la vie privée...
Des fois je me demande si c'étais pas mieux avant... :p
Facebook, mon c*l...
Hop, pour commencer Facebook est TOUT sauf sécurisé et préocupé de garantir la protection de votre vie privée; c'est une entreprise marketing puissante qui n'hésite pas a revendre votre profile a des bureaux d'études situés a l'autre bout du monde...
Il y a quelques temps, j'ai lu que les développeurs d'applications FB allaient avoir accès a des données confidentielles de votre profile, MEME si vous les avez mis en privé... Fiction ? Hélas non...
une peuve ?
Grace a vos amis, les applications peuvent avoir accès a tout ce que vous ne vouliez pas qu'elles aient acces; je m'explique.
Dans le menu en haut a droite, cliquez sur "Compte".
![]()
Choisisez l'option "Paramètres de confidentialité"
 Normalement vous avez déjà sécurisé un minimum votre compte:
Normalement vous avez déjà sécurisé un minimum votre compte:
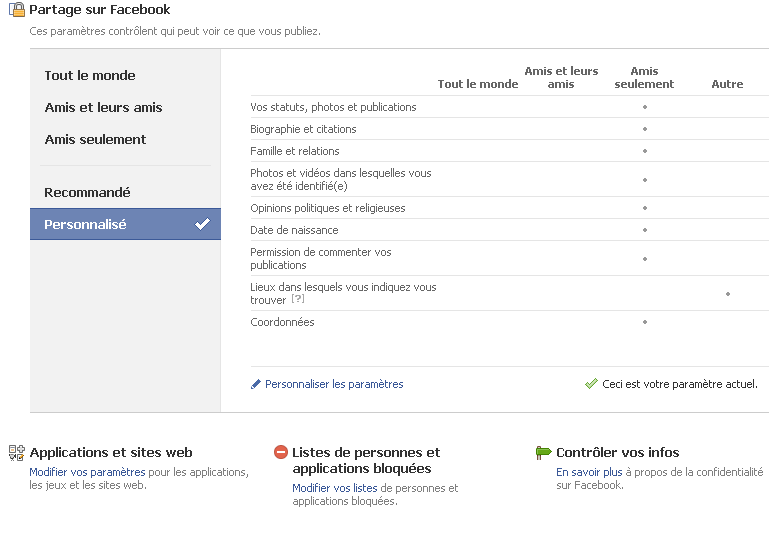 si vous regardez en bas a droite de cet écran, vous y verrez "Applications et sites web"... Suivez le lien "Modifier vos paramètres".
si vous regardez en bas a droite de cet écran, vous y verrez "Applications et sites web"... Suivez le lien "Modifier vos paramètres".
Une nouvelle page se charge, dans cette page vous allez trouver une série d'options pour configurer la sécurité faces aux applications.
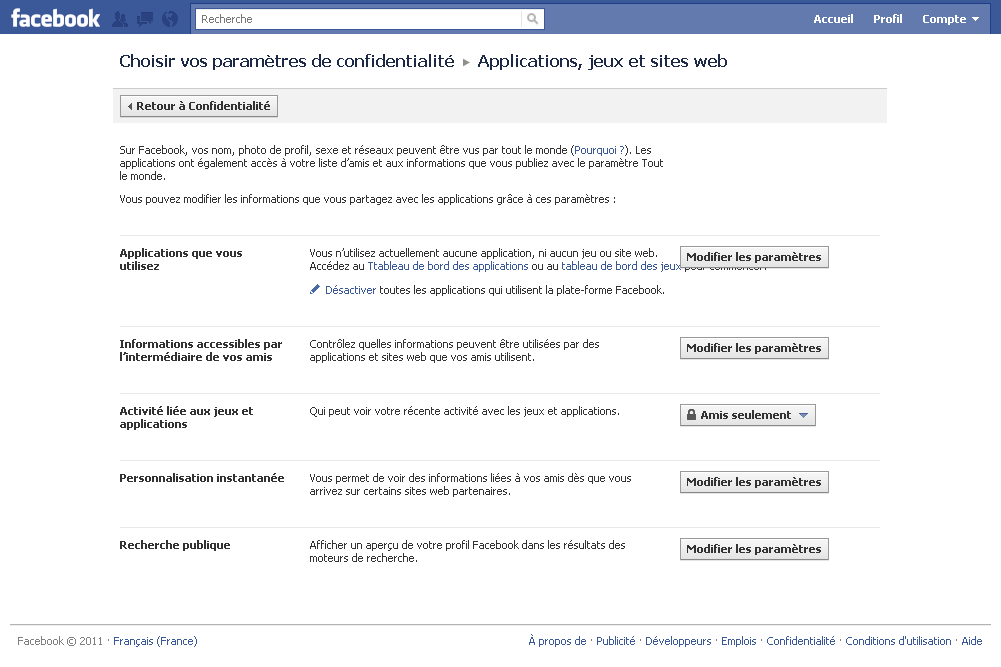 Je vous invite a cliquez sur le bouton en face de la seconde rubrique: "Informations accessibles par l'intermédiaire de vos amis", vous allez découvrir, sans doute avec horreur, l'étendue de ce que les applications (et donc les bureaux d'étude markerting) recoivent de vos amis qui vous spamment avec des applications a la c*n.
Je vous invite a cliquez sur le bouton en face de la seconde rubrique: "Informations accessibles par l'intermédiaire de vos amis", vous allez découvrir, sans doute avec horreur, l'étendue de ce que les applications (et donc les bureaux d'étude markerting) recoivent de vos amis qui vous spamment avec des applications a la c*n.
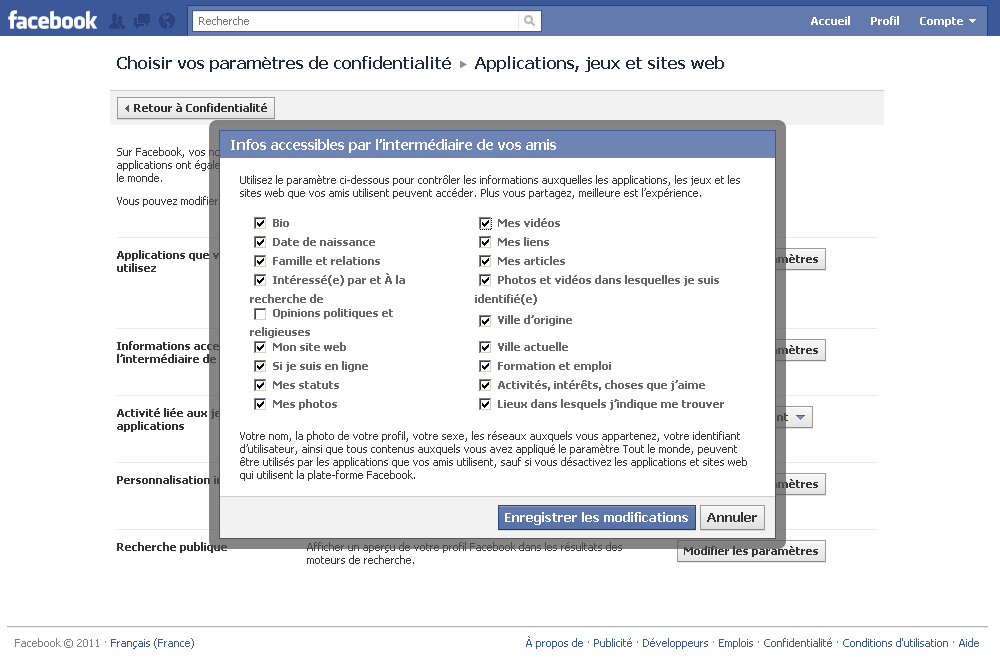 On pourrait raisonnablement se poser la question du pourquoi, par défaut, les applications de VOS amis ont accès a vos données...
On pourrait raisonnablement se poser la question du pourquoi, par défaut, les applications de VOS amis ont accès a vos données...
Mais ce serait comprendre que Facebook est une entreprise commerciales qui vous vends VOUS...
Divers
Entreprise Vault
Déplacer une partition sur le même serveur
Problème
Vault est une vrai bénédiction pour les admins, jusqu'a ce que les disques (ou partitions) soient eux aussi saturés...
Avant qu'il ne soit trop tard, il convient de faire un peut de ménage, en déplacant l'une ou l'autre ancienne partition vers des disques plus lents ou moins couteux... Mais sur le même serveur.
Solution
Bien qu'il n'existe aucun "wizard" pour ce faire, ce type de migration de données est assez facile, car contrairement aux fichiers utilisateurs, vous avez un controle total sur le serveur.
-
Placer le serveur Vault en mode "Backup" (AKA read-only);
-
Redémarrer les services VAULT.
-
Faite un bon backup complet (on ne sait jamais...)
-
Vérifiez la table "Watchfile" en utilisant le "SQL Server Enterprise Manager (SQL 2000)" ou "SQL Server Management Studio (SQL 2005)", si vous avez trop de données suivez ce technote http://www.symantec.com/docs/TECH68204 pour "nettoyer".
- Copiez la partition "Vault" vers sa nouvelle location, si il s'agit d'une partition "fermée" vous pouvez faire cette opperation en premier puisque la partition ne sera pas modifiée et conserver le serveur "actif" le plus longtemps possible...
- Stopez tout les service Enterprise Vault..
- Re ouvrez le "SQL Server Enterprise Manager (SQL 2000)" ou "SQL Server Management Studio (SQL 2005)"
- Navigez dans Databases | EnterpriseVaultDirectory | Tables
- Ouvrez la table VaultStoreEntry et lister toutes les lignes...
Note: Le VaultStoreEntryId correspond a un VaultStoreName. Notez scrupuleusement l'ID (Figure1) et refermez la table.
Figure 1

- Ouvrez la table PartitionEntry et lister toutes les lignes... cherchez le bon VaultStoreEntryI
Note: le VaultStoreEntryId correspond a un PartitionRootPath. Il vous suffit de modifier le chemin de cette colonne vers le nouveau chemin de la partition (Figure 2)
Figure 2

- Executez la requete une fois de plus pour vous assurez du changement.
- Remettre le Serveur en mode Read/Write; désactivez le mode backup.
- Re-démarrez les services Vault.
- Vérifiez scrupuleusement les logs d'applications et le bon fonctionnement du Vault.
- Après quelques test concluants, vous pouvez détruire l'ancienne partition.
Modifié AEVA gallerie pour loggué tout
Ayant eut quelques visiteurs indélicats sur ma gallerie, j'ai décidé de mettre en oeuvre une sorte de logs; j'ai aussi écrit un outils qui permet d'avoir une vue sur les x derniers accès, avec géolocalisation; je ferais sans doute un article plus complet sur cet outils plus tard.
AEVA est sans doute l'une des gallerie les plus performantes que j'ai eut a installer; mais elle ne reseigne que le nombre de 'vues' sur une image/video, en aucun cas, la localisation du visiteur; de mon point de vue, plus on en sait; mieux c'est; j'ai donc modifié aeva gallerie pour que celui-ci loggue chaque demande dans une table...
voici le "how-to" (pour une version 1.4c)
commençons par la table qui va contenir le log:
CREATE TABLE IF NOT EXISTS `media_log_visit`(
`stamp` int(11) NOT NULL,
`IP` varchar(16) character set latin1 collate latin1_german1_ci NOT NULL,
`id` int(11) NOT NULL,
`referer` varchar(1024) collate latin1_general_ci default NULL,
`useragent` varchar(1024) collate latin1_general_ci default NULL,
KEY `stamp` (`stamp`),
KEY `IP` (`IP`),
KEY `id` (`id`),
KEY `referer` (`referer`(1000)),
KEY `useragent` (`useragent`(1000))
) ENGINE=MyISAM DEFAULT CHARSET=latin1 COLLATE=latin1_general_ci;
Ensuite nous modifions les fichiers:
MGalleryItem.php
ligne 36:
$id = isset($_REQUEST['id']) ? (int) $_REQUEST['id'] : (int) $_REQUEST['in'];
$type = isset($_REQUEST['thumb']) ? 'thumb' : (isset($_REQUEST['preview']) ? 'preview' : 'main');
Insérez juste avant if (!aeva_allowedTo('access'))"
// Fixed by Frater
$amFunc['db_query']('
UPDATE {db_prefix}aeva_media
SET views = views + 1
WHERE id_media = {int:media}',
array('media' => $id),__FILE__,__LINE__);
/* IP Logs by Frater */
$ip = "UNKNOWN";
if ($_SERVER["HTTP_CLIENT_IP"]) $ip = $_SERVER["HTTP_CLIENT_IP"];
if ($_SERVER["HTTP_X_FORWARDED_FOR"]) $ip = $_SERVER["HTTP_X_FORWARDED_FOR"];
if ($_SERVER["REMOTE_ADDR"]) $ip = $_SERVER["REMOTE_ADDR"];
$referer = $_SERVER['HTTP_REFERER'];
$useragent = $_SERVER['HTTP_USER_AGENT'];
$log_date = time();
$query_sql = "INSERT INTO {db_prefix}log_visit
(stamp,IP,id,referer,useragent)
VALUES ($log_date,'$ip',$id,'$referer','$useragent')";
$amFunc['db_query']($query_sql,
array('id' => $id),__FILE__,__LINE__);
// Nothing more to come
en ligne 93; supprimé le block:
$amFunc['db_query']('
UPDATE {db_prefix}aeva_media
SET views = views + 1
WHERE id_media = {int:media}',
array('media' => $id),__FILE__,__LINE__);
// Nothing more to come
Aeva-Gallery.php
autour de la ligne 2190; rechercher:
die('Hacking attempt...');
$type = current(array_intersect(array('thumb', 'thumba', 'preview', 'icon', 'bigicon', 'main'), array_keys($_REQUEST)));
$type = $type === false ? 'main' : $type;
// Get the file's data
$id = (int) $_REQUEST['in'];
/* IP Logs by Frater */
$ip = "UNKNOWN";
if ($_SERVER["HTTP_CLIENT_IP"]) $ip = $_SERVER["HTTP_CLIENT_IP"];
if ($_SERVER["HTTP_X_FORWARDED_FOR"]) $ip = $_SERVER["HTTP_X_FORWARDED_FOR"];
if ($_SERVER["REMOTE_ADDR"]) $ip = $_SERVER["REMOTE_ADDR"];
$referer = $_SERVER['HTTP_REFERER'];
$useragent = $_SERVER['HTTP_USER_AGENT'];
$log_date = time();
$query_sql = "INSERT INTO {db_prefix}log_visit
(stamp,IP,id,referer,useragent)
VALUES ($log_date,'$ip',$id,'$referer','$useragent')";
$amFunc['db_query']($query_sql,
array('id' => $id),__FILE__,__LINE__);
/* IP Logs by Frater */
// Nothing more to come
Voilà c'est fait
Outlook et ses polices
Vous avez Outlook 2003?
Vous désirez y déployer une police particulière sur des dizaines de PC?
facile:
sur un outlook vous configuré les polices suivant votre envie...
vous lancez regedit, naviguez jusqu'a la clé suivante:
HKEY_CURRENT_USER\Software\Microsoft\Office\11.0\Common\MailSettings
vous extrayez les trois clés binaires suivantes:
ComposeFontSimple
ReplyFontSimple
TextFontSimple
Vers un fichier font_outlook.reg
Ensuite sur chaque PC il vous suffit d'excuter la commande suivante:
regedit /s fichiers.reg
Quicktime et Real-player
j'en ai eut marre...
Marre de REALplayer et de sa pub qui s'affiche partout, ...
Marre de Quicktime et de ses saloperies de Itunes qui sont "obligatoire" sans obligation d'achat mais qui pourrissent votre PC...
Marre de regarder un quicktime via une interface bof...
Une bonne solution:
les versions 'alternative'...
Quicktime Alternative et Real Alternative...
http://www.clubic.com/lancer-le-telechargement-18506-0-quicktime-alternative.html
http://www.clubic.com/lancer-le-telechargement-35320-0-real-alternative.html
Note:
quand j'ai écris cette note, je ne connaissait pas VLC... maintenant je suis devenu fan...
il existe aussi VLC (http://www.videolan.com) qui est tres bien...
IWSS (Interscan Web Security Suite 5.5) Virtual Appliance...
...
ISMPeek
Usage: ismpeek.sh [-h] [-F] [-c count] [-m count] [-n period] [-d display_format] [-w filename]
display format used is "Drnysucaz"
Options:
-h Print this help page
-F Display metrics for FTP (by default, HTTP metrics are displayed)
-c Display the column headers every [count] iterations. Default is to display column
headers only on the first iteration
-m Exit ismpeek after [count] iterations. Default is to run until manually interrupted.
-n A new line is printed every [period] seconds, or 5 seconds by default
-w Save output to [filename] instead of stdout
-d Change the columns printed by using any combination of characters [DrRnNyYlLbBsSeEuUzZwWxXtcaCqg]
D DATETIMESTAMP - the time at which this line was output
R REQ_C - the cumulative average of total time IWSS spent handling each transaction, in ms
r REQ_A - the average of total transaction handling time for the last [period], in ms
N DNS_C - the cumulative average time spent on each DNS lookup prior to connecting, in ms
n DNS_A - the average DNS lookup time for the last [period], in ms
Y CON_C - the cumulative average time spent on establishing tcp connections, in ms
y CON_A - the average tcp connection time for the last [period], in ms
L LDAP_C - the cumulative average time spent per LDAP query, in ms
l LDAP_A - the average LDAP query time for the last [period], in ms
B PRE_C - the cumulative average time spent in each pre-scan job, including URL filtering lookup, in ms
b PRE_A - the average pre-scan time for the last [period], in ms
S SCAN_C - the cumulative average time spent in each scan job, including VSAPI and AAXS
s SCAN_A - the average scan job time for the last [period], in ms
E POST_C - the cumulative average time spent in post-scan accounting, in ms
e POST_A - the average post-scan job time for the last [period], in ms
U RATE_C - the cumulative average time spent handling URL rating requests to the remote rating server, in ms
u RATE_A - the average URL rating request time for the last [period], in ms
Z WT/NS/SY/LD/RT/SC% - The percentage of total cumulative request time spent in the activities of
Waiting for network IO(WT), DNS lookup (NS), tcp connecting (SY), LDAP lookup (LD), URL rating (RT), and scanning (SC)
z WT/NS/SY/LD/RT/SC% - The percentage of time spent in io wait, DNS, tcp connect, LDAP, URL rating, and scanning for the last [period]
W NB/DK/BL/NS/ES% - The percentage of total cumulative time spent in nonblocking IO, disk IO,
blocking IO (ldap, access quota), normal scan, and expensive scan stages
w NB/DK/BL/NS/ES% - The percentage of time spent in nonblocking IO, disk IO,
blocking IO (ldap, access quota), normal scan, and expensive scan stages for the last [period]
X TX_TOTAL_C TX_BLOCK_C - The cumulative number of transactions handled and blocked, respectively
x TX_TOTAL_A TX_BLOCK_A - The number of handled and blocked transaction during the last [period]
t THRU_IN - the throughput received from servers for the last measured interval, in bytes per second.
THRU_OUT - the throughput received from clients for the last measured interval, in bytes per second
Throughput is calculated over 5 second intervals, regardless of the [period] setting.
If [period] is not a multiple of 5, then THRU_IN and THRU_OUT will sometimes be
reported as 0, because the latest throughput calculation interval has not yet elapsed
c CONNS - the number of clients currently connected to the proxy
a ACTIVE - the number of sessions connected to the client that are at least partly through
a transaction, and not merely waiting for a follow-on client request to arrive on a keep-alive
connection
C {CLI,SRV,PXY,TMO}_CLOSE - the number of sessions closed by action from the client, server, proxy, or timeout
q LSTNQ - the number of newly established sessions waiting to be handled by any thread
NBIOQ - the number of sessions waiting for a non-blocking IO stage thread to handle them after
returning from any other stage
DIOQ - the number of sessions waiting to be handled by a disk IO stage thread
BIOQ - the number of sessions waiting to be handled by a blocking IO (ldap, access quota, user-id) stage thread
NSCNQ - the number of sessions waiting to be handled by a normal scanning stage thread
ESCNQ - the number of sessions waiting to be handled by an expensive scanning stage thread
ACCTQ - the number of objects waiting to be processed by an accounting stage thread
g AL/BL/VL/AQ - the number of pending logs dropped due to event generation speed
exceeding logging/database update speed. AL = access, BL = URL or WRS block,
VL = virus log, AQ = access quota consumption update
k RSKA - the current number of idle keep-alive rating server sockets
IWSS - current transaction
Pour voir les transaction en cours par le systeme:
Rendez vous dans le dossier de iwss, vous y trouverez une commande stpeek... qui permet de voir les transaction en cours...
Prints, in tab separated format, the status of each proxied
transaction that is actively handled by IWSS ftp or http proxy
New sessions that are queued will not be displayed
Options:
'F' - print session table for the FTP proxy process
'x' - Don't copy the session table shared memory to process local memory before printing - NOT RECOMMENDED
'h' - Print this informational page
'm' - Print the session table a maximum of [count] times, every [period] seconds.
Default is to print only print the table once. To change [period] use the 'n' option
'n' - Specify the [period] of seconds to peek at the session table. Default is 5 seconds
'w' - Print session table output to the file specified in [filename] instead of to the console
Columns printed:
SEQ:PID or CPID:PPID - The sequence number and process number of the state object attached to
this session. For process-per-session mode daemons this is replaced by the child process
and parent process pids
STATUS - The current status of the transaction. Supported values include:
DISCON - Not connected. These nodes are normally never displayed
RCV_REQ - Waiting for incoming client HTTP or ICAP request
DNS - Resolving the domain name of the HTTP server
CON_SRV - Connecting to the HTTP server
SND_REQ - Relaying the complete client request to the HTTP server
PRL_REQ - Relaying the client request to the HTTP server before
the request has been completely received by IWSS
RCV_RSP - Receiving the HTTP response from the server
SND_RSP - Relaying the complete HTTP or ICAP response from the server to the client
PRL_RSP - Relaying the partial HTTP response from the server to the client
before the entire response has been received by IWSS
SND_100 - Sending a 100 Continue HTTP or ICAP response to the client
TUNNEL - The session is an unexamined HTTPS or non-HTTP protocol transaction
which is tunneled by IWSS
FTPHTTP - An FTP over HTTP transaction
TXDONE - Transaction is complete but not yet reset
PRL_ICAP - Sending an ICAP response before the complete ICAP request has been
received by IWSS
FTP_CMD - Handling the command channel for an FTP session
CON_CMD - Connecting the command channel to the FTP server - includes DNS
DC_SRV - Connecting the passive-mde data channel to the FTP server
DC_CLT - Connecting the active-mode data channel to the FTP client
DL_SRV - Waiting for an active-node data connection from the FTP server
DL_CLT - Waiting for the passive-mode data connection from the FTP client
FTP_UL - Performing an FTP upload
FTP_DL - Performing an FTP download
PS_TXLOG - Writing the transaction log
PS_AQINF - Preparing access quota info
PS_AQENF - Enforcing the access quota
PS_URLS - Checking URL lists
PS_RATE - Performing TMUFE/WRS score query
PS_PLUGIN - Running PreScan plugins
PS_SKIP - Checking skip-scan rules
SC_VIRUS - Performing virus/spyware scan
SC_AAXS - Performing AAXS scan
SC_ITL - Perfoming IntelliTunnel scan
C_SOCK - Descriptor number of the client socket
CLIENT_ADDR - IPv4 address of the client connection
S_SOCK - Descriptor number of the server socket. For FTP proxy this is only the
command channel. For ICAP this is unused.
SERVER_ADDR - IPv4 address of the server connection. For FTP proxy this is
only the command channel. For ICAP this is unused.
LCL_PORT - The local port number used for the server connection
STAGE - The current stage handling the session. This is only used in WorkQueue
daemons, designated by command line option -m for the proxy process
STGTIME - The number of seconds the session has been in the current stage.
This is only used in WorkQueue daemons, designated by command line option
-m for the proxy process
CONTIME - The number of seconds that this client session has been actively handled
IOWAIT - The number of milliseconds since the last I/O event related to this session was handled
THRUBYTE - The number of bytes written to any socket during this transaction
THRUPUT - The number of bytes per second written during the current transaction
FLAGS - Flags set for this session. Currently supported flags:
IDL - The session is idle, waiting for a client request
SSL - The session is HTTPS
SKP - Scanning of this transaction has been skipped due to configuration
TBP - The session is non-HTTP binary protocol tunneled over port 80
AGC - Apollo Guidance Computer
Bonjour,
Actualité (passée) oblige, tous le monde, y va de son petit truc sur l’exploit d’Apollo 11.
Personnelement, je trouve cette partie de l’Histoire de l’humanité particulièrement existante et intéressante, et de mon point de vue de petit humain,un évement sans précédent dans TOUTE l'histoire de l'Humanité.
En tant que professionnel, je ne peux que resté impressionner par la dimension de l'exploit, alors que les hommes de la NASA n'avaient RIEN pour se baser.
Il ne faut surtout pas oublié que durant les années 1960s, un ordinateur, ca ressemblait surtout à ca:
 Je vous présent l'ordinateur phare d'IBM dans les années 1960s, la Série IBM 360 Modèle 30, Série concu au début de la décénie, et mise sur le marché en 1964.
Je vous présent l'ordinateur phare d'IBM dans les années 1960s, la Série IBM 360 Modèle 30, Série concu au début de la décénie, et mise sur le marché en 1964.
A sa sortie, le modèle 30 pesait seulement 770kg, Il a eut deux grands frères plus puissant, les modèles 40 et 50 pesant respectivement 1 tonne et 3,2 tonnes), d’autres modèles (les modèles 60, 70, 90) ont fait partie du catalogue, mais n’ont jamais été construit car jamais commandés.
En 1969, le modèle le plus puissant disponible chez IBM etait le 360 modèle 85, sorti en janvier 1968, il affichait un poids de 6,5 tonnes pour le processeur uniquement.
Impossible d’aller sur la lune avec un tel monstre a bord, et surtout lorsque l'on connait la fiabilité et la consomation de ce genre de bestiaux.
Les gars de la NASA ont dû innover (comme dans beaucoup de partie du programme d’ailleurs).
et de cet inovation est né l'AGC [Apollo Guidance Computer]; des dérivés trsè simplifiés de l'AGC ont équipés les missiles intercontientale américain jusqu'au début des années 1990s.
L'AGC etait tellement en avance sur son temps (logique transistor) que beaucoup de concepteurs (dont un certain Steve Wozniak) peuvent prétendre être les héritiers, notament pour l'usage intensif des transistor et des circuits intégrés.
Aujourd’hui, je trouve dommage que l'AGC ne soit pas étudier dans les écoles, tellement c'est un ordinateur moderne par bien des aspects, mais qui par d'autres aspects est une superbe usine a gaz.
Par bien des aspects, l'AGC est sans doute le premier micro ordinateur qui a (réelement) permis de voyager au delà des frontières connues.
Quand on regarde les spécifications de l’AGC, hummm ca sent tellement bon les années 60 :
|
CPU |
15 bits |
|
RAM |
2048 mots (de 15 bits) |
|
ROM |
36864 mots (avec switch de banque mémoire) |
|
Poids |
32 Kg |
Il existe une vidéo sur Youtube qui explique bien cet ordinateur, et qui démontre aussi que le développement du programme Apollo (ainsi que des éléments qui l’ont composés) s’est fait souvent de façon anarchique ; il suffit de voir le passage sur les instructions « extended » pour comprendre qu’ils ont dû ajouter plusieurs instructions non prévue à la base…
Dans cette vidéo on découvre que l'AGC avait déjà du mutlitache preemtifs (ce que Microsoft n'a mis en place que dans les années 1990) mais aussi des "machines virtuelles", ce qui en fait un ordinateur très moderne pour un ancêtre...
Television - Décodeurs - etc
Il y a encore 10 ans, les télévisions étaient diffusées en mode analogiques, que ce soit sur le cable ou via les onde radio...
Cette belle époque, où tout était presque facile, est hélas révolue...
TNT, DVB-C, DVB-S, DVB-T, aujourd'hui on se croirait dans un concours de récitation de l'alphabet...
Televiseur Samsung Serie 7
Entrer dans le mode 'Option'
Si votre téléviseur est europeen, voici la marche a suivre:
- Eteignez votre Téléviseur (attendez que celui-ci soit réelement éteint)
- Sur votre Télécommande, pressez rapidement les touches suivantes:
- INFO
- MENU
- MUTE
- Rallumez votre Téléviseur
Nox Category:
Activer les bonnes connections sur votre téléviseur
Internet@TV ne fonctionne pas chez vous et reste toujours sur 'Connection'... voici la marche a suivre.
Une fois en mode 'Options', un menu bleu va s'afficher sur la partie gauche de l'écran.
vous avez le choix entre plusieurs menu...
- Entrez dans le menu 'option' et changer la ligne 'medialink' vers 'INFOLINK ON'.
- Pressez 'Return' pour retourner au menu principal.
- Descendez dans le menu principal sur l'option 'CONTROL',
- Choisisez ensuite 'Sub-Option' (cela affichera une longue liste de choix et d'options)
- Vers la fin de la liste, vous y trouverez 'INFOLINK COUNTRY': choisisez votre pays.
- Dans le même menu 'suboption', rechercher l'option 'INFOLINK SERVER TYPE', vérifiez que vous êtes bien sur 'Operating'.
- Eteignez votre TV, lors du prochain allumage, Internet@TV doit fonctionner correctement.
Nox Category:
AZBox
Parmis tout les décodeurs qui existent, il y a bien sur les DreamBox, très puissantes, et qui sont les plus faciles a trouver; mais un petit constructeur a sortis une box bien moins couteuse et très prometteuse: l'AZBox...
Je viens d'acquérir un de ces appareils, un Premium + avec deux décodeurs DVB-C.
Voici mon expérience sur ce type de matériel...