VMWare ESX(i) 4, 5 et Workstation
![]()
Depuis bientôt deux ans, j'utilise vmware comme base pour la consolidation et virtualisation des serveurs a mon bureau.
Je connais VMWare depuis bien plus longtemps que ca, en 1997 ou 1998, nous utilisions VMWare Workstation comme laboratoire virtuel pour le développement, ainsi que pour faire tourner de vieux jeux DOS qui ne supportaient pas Windows NT, ou certaines applications qui ne fonctionnaient pas avec la mythique Gravis Ultra Sound (GUS) [1].
La version ESX 5 offre pas mal de (bonnes) nouveautées, citons en quelques unes:
- bonne optimisation des VM 64x (principalement en Windows 2008-2008 R2, 7). Les VMs sous debian semble moins impactées par ces optimisations; faut bien dire que la console sous 2008 en ESX 4 ramaient sévère.
- Amélioration de la gestion AERO, là aussi on attendait largement une révision des drivers graphiques de VMWare.
- intégration des OSX en mode natif, donc plus aucun "expoit" a installer un OSX sur VMWare (grrr) quoi que...
- Gestion des volumes VMFS de plus de 2 TB (enfin)
Parmis les "mauvaises" surprises:
- changement du systeme de licences, la mémoire RAM est également prise en compte, plus uniquement les CPUs (physiques), cela semble toutefois moins lourds qu'annoncer
- Le vCenter qui passe en 64bits uniquement (bonjour l'extra licence windows 2008 pas prévue dans le budget)
Je parlerais aussi de son petit frère; la version Workstation (et de l'outsider VirtualBox)
[1] Note pour moi-même, je ferais bien un article sur cette carte exceptionnelle.
[ESX4] OSX sous VMWare (Esx 4.1)
Je vais faire un 'how-to' un de ces quatres, mais voici une petite fiertée... il parrait que ce n'est pas si simple finalement...
[ESX] Authoriser la connection root en ssh
Ca y est, votre ESX est correctement configuré (ou peu s'en faut), vous devez vous connecter pour finaliser deux trois détails, pour avoir une console plus grande, et un meilleurs confort (en effet les serveurs sont a la cave, difficile d'accès ou leurs consoles 'local' n'est même pas cablée, vous choisisez d'utiliser 'ssh'... et votre password 'root' ne fonctionne pas... (alors que le même mot de passe utiliser plutot sur la console local fonctionne bien)
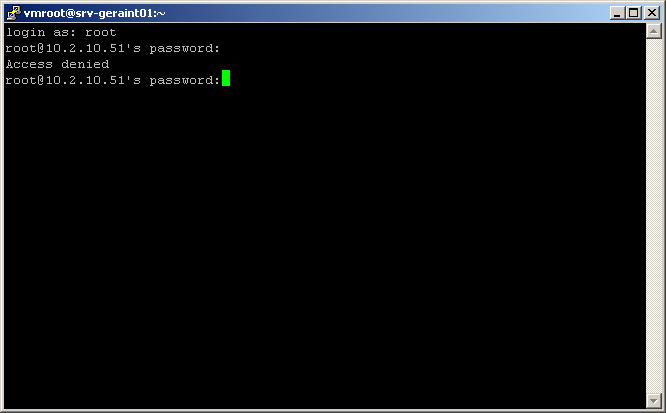
Mais pourquoi dites vous... Etes vous fatigué a ce point d'avoir taper un mauvais mot de passe... ou bien est ce que l'ESX refuserait le login en ssh pour le root ?
C'est en fait cette derniere option qui est la bonne... depuis la version 3 des ESX, pour augmenter la sécurité, il est impossible de se connecter en root via le service ssh, si votre ESX est accessible a tous via n'importe quoi; c'est effectivement une bonne solution, mais si vous penser que c'est un peu 'too much' alors voici la marche a suivre.
Si vous avez créer lors de l'installation un autre compte connectez vous en ssh avec
votre premiere commande sera de passer en mode root:
Si vous n'avez pas créer de compte 'de secours'; vous n'avez alors pas d'autre choix que de vous connectez s en root sur la console du host (ou de créer un compte via le client vSphere pour ensuite vous connecter avec).
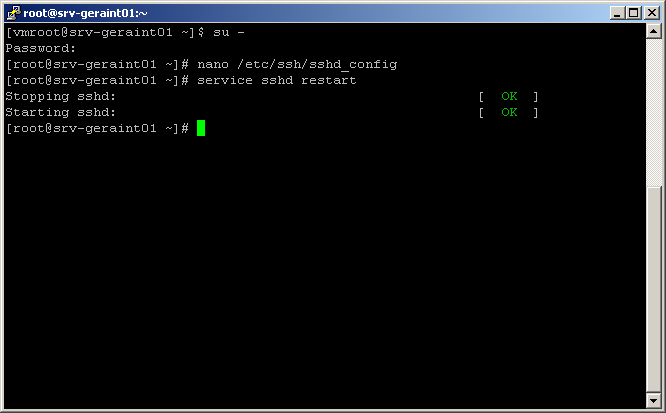
Editez ensuite le fichier de configuration du deamon ssh, avec la commande suivante par exemple
Chercher la ligne PermitRootLogin no et changer le 'no' en 'yes'; sauvegarder les changements (Ctrl-O); nano va vous proposer d'éditer le nom du fichier a sauvegarder, ne changez rien; et pressez Enter, vous pouvez quitter nano avec Ctrl-X.
Il ne vous reste plus qu'a redémarrer votre deamon ssh:
Et voila
[ESX] Connecter le service console a un vlan APRES installation
Si comme moi, vous avez une configuration ESX un peu complexe, vous avez plus que certainement des VLANs pour la gestion du "reseau"... et vous n'utilisez pas le même VLAN que celui par défaut, dans mon cas le VLANID est 1, de même le vMotion est sur le VLANID 10.
Si comme moi, lors de l'installation de votre ESX en mode 'next-next-config-next'; vous avez peut-etre raté la configuration du VLAN, et que vous ne savez pas connecter votre nouveau ESX via le network; il va falloir pratiquer la configuration unix; ceux qui connaissent Debian, redhat ou centos, sans la version graphique, savent de quoi je parle, pour les autres; voici comment configurer votre System Console -> LAN.
connectez vous en root, sur la console physique du serveur (via le réseaux, ce n'est pas encore possible acause de votre oubli)
ESX utilise une carte réseau virtuelle pour se connecter, un simple ifconfig vous le prouvera; outre le traditionnel lo (pour loopback), vous allez voir l'ensemble de vos interfaces physiques nommés 'vmnicx' ainsi qu'un interface au nom étrange: vswif0; il s'agit de votre interface 'service console' qui par défaut est rataché a l'interface que vous avez précisé lors de l'instalation
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:4539 errors:0 dropped:0 overruns:0 frame:0
TX packets:4539 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:10178211 (9.7 MiB) TX bytes:10178211 (9.7 MiB)
:
vmnic3 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7004 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:861771 (841.5 KiB) TX bytes:0 (0.0 b)
Interrupt:201
vswif0 Link encap:Ethernet HWaddr xx:xx:xx:xx:xx:xx
inet addr:10.2.10.51 Bcast:10.2.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8970 errors:0 dropped:0 overruns:0 frame:0
TX packets:6363 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1711522 (1.6 MiB) TX bytes:5477550 (5.2 MiB)
Switch Name Num Ports Used Ports Configured Ports MTU Uplinks
vSwitch0 64 1 32 1500 vmnic2
PortGroup Name VLAN ID Used Ports Uplinks
Service Console 0 1 vmnic2
VMotion 1 0 vmnic2
# esxcfg-vswitch -v 10 -p VMotion vSwitch0
Switch Name Num Ports Used Ports Configured Ports MTU Uplinks
vSwitch0 64 1 32 1500 vmnic2
PortGroup Name VLAN ID Used Ports Uplinks
Service Console 1 1 vmnic2
VMotion 10 0 vmnic2
[ESX] Conseils d'installation: SNMP bavard
Lors de la configuration d'un host ESX, il y a certaines options qui peuvent vous pourrir la vie... ou plutôt remplir des logs de truc inutiles...
SNMP est un bon exemple si vous regardez dans le fichier messages [/var/log/messages] vous allez y trouver
...toutes les deux secondes... C'est assez barbant et totalement inutile...
sur ESX 4.1:
cherchez une ligne qui ressemble à:
Retirez le "-a", votre ligne devra ressembler à:
Faites la combinaison de touche Ctrl-O, pressez Enter (pour sauver) et Ctrl-X pour quitter.
Il ne reste plus qu'a re-démarrer votre service snmp:
[ESX] Installer les HP Tools
Si comme moi, vous avez des serveurs HP, vous allez pouvoir installer les HP tools...
Comme toujours on commence par copier le fichier .tgz télécharger chez HP sur le local datastore.
et on le décompresse normalement:
cela va créer une structure /hpmgmt/860/ qu'il faudra navigué et ensuite executer l'installation:
# ./install860vibs.sh --install
HP Insight Manager Agent 8.6.0-11 Installer for VMware ESX
Target System is VMware ESX 4.1.0 build-348481
Server: ProLiant DL380 G5
This script will now attempt to set ESX Host in Maintenance Mode
for IM agents install.
Do you wish to continue? (y/n) y
System is already in Maintenace mode.
Installing HP Insight Manager Agents bulletin [classic-mgmt-solution-860.11.0508]
....OK
/opt/hp/hp-agents-config /vmfs/volumes/System 02/hpmgmt/860
Si vous désirez installer la HP homepage, c'est ici que ca se passe:
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for hpim service (2381) in the firewall [ OK ]
For allowing discovery by HP System Insight Manager, the port (2301)
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for HP System Insight Manager (2301) in the firewall [ OK ]
For the Insight Manager agents to communicate properly with HP Systems Insight
Manager, the snmpd service should be enabled in the firewall.
Maintenant, nous allons configurer le SNMP:
Enabling snmpd service in the firewall [ OK ]
For adding the HP Systems Insight Manager Certificate in SMH, the port [280]
should be enabled in the firewall.
Do you want to enable this port? <y/n> (default is y) y
Enabling port for SIM Certificate in SMH [280] in the firewall [ OK ]
This configuration script will configure SNMP to integrate with the HP SIM and
the HP System Management Homepage by editting the snmpd.conf file. The HP-SNMP-Agents can also exist in a more secure
SNMP environment (e.g. VACM) that you have previously configured. See the
hp-snmp-agents(4) man page for specific details on how to configure the VACM entries
in the 'snmpd.conf' file. You may press <ctrl+c> now to exit now if needed.
Do you wish to use an existing snmpd.conf (y/n) (Blank is n):
these question will affect the way SNMP behaves. Configuring SNMP could have
security implications on your system. If you are not sure how to answer a
question, you can abort by pressing <Ctrl-c> and no changes will be made to
your SNMP configuration.
Enter the localhost SNMP Read/Write community string
(one word, required, no default):
Re-enter the same input to confirm:
ACCEPTED: inputs match!
Au cas ou vous auriez un doute, ou un trou de mémoire, vous pouvez préciser la valeur par défaut pour l'accès read/write : private
(one word, Blank to skip):
Re-enter the same input to confirm:
ACCEPTED: inputs match!
Vous pouvez préciser la valeur par défaut pour l'accès read : public. Bien sur ces deux valeurs peuvent être choisie selon vos envies ou besoin.
(Blank to skip):
Enter Read Only Authorized Management Station IP or DNS name
(Blank to skip):
Enter default SNMP trap community string
(One word; Blank to skip):
Enter SNMP trap destination IP or DNS name
(One word; Blank to skip):
The system contact is set to
syscontact Root <root@localhost> (configure /etc/snmp/snmp.local.conf)
Do you wish to change it (y/n) (Blank is n):
The system location is set to
syslocation Unknown (edit /etc/snmp/snmpd.conf)
Do you wish to change it (y/n) (Blank is n):
==============================================================================
NOTE: New snmpd.conf entries were added to the top of /etc/snmp/snmpd.conf
==============================================================================
snmpd is started
[ OK ]
Stopping System Management Homepage: [ OK ]
Starting HP Insight Manager agents: [ OK ]
Starting System Management Homepage: [ OK ]
Stopping SNMP stack:
Stopping snmpd: [ OK ]
Starting SNMP stack:
Starting snmpd: [ OK ]
**********************************************************
* System Management Homepage installed successfully with *
* default configuration values. To change the default *
* configuration values, type the following command at *
* the root prompt: *
* *
* /opt/hp/hpsmh/sbin/smhconfig *
* *
**********************************************************
Please read the License Agreement for this software at
/opt/hp/hp-health/hp-health.license
By not removing this package, you are accepting the terms
of the "License for HP Value Added Software".
HP Insight Manager agents have been configured successfully!
/vmfs/volumes/System 02/hpmgmt/860
HP SNMP agents are installed and configured
Reboot the system to make the changes effective.
C'est ici qu'il faut passer par la reconfiguration du snmpd... sinon votre messages logs va etre flooder... (voir ce lien)
Vous pouvez également faire un clean de votre datastore:
# rm -f hpmgmt-8.6.0-vmware4x.tgz
[ESX] Mettre a jour vers 4.1 via ssh
Oui je sais il existe un outils tout fait... Mais j'avoue que là, j'hésite encore a m'en servir... J'ai en effet du re-installer complètement un host suite à l'usage (foireux) de cet outils, donc, je ne suis pas convaincu que ce soit la bonne idée...
Téléchargez les fichiers suivant sur un volume local de votre ESX:
upgrade-from-ESX4.0-to-4.1.0-0.0.260247-release.zip
Dans mon cas je les ai copié sur le volume VMFS"System 01"
Si votre serveur n'est pas encore en mode maintenance:
vous pouvez aussi le faire via le client VSphere.
pour accéder au volume VMFS "System 01", vous devrez suivre le chemin suivant:
/vmfs/volumes/System\ 01/
notez la présence d'un '\' en plein milieu, ce caractère permet de placer un espace dans le chemin sans que le système y voit un séparateur...
lancez la pre-upgrade et laissez faire:
Unpacking vmware-esx-esxupdate-4.1.0-0.0.260247.i386.vib ########## [100%]
Unpacking vmware-esx-uwlibs-4.1.0-0.0.260247.i386.vib ########## [100%]
Unpacking glibc-common-2.5-34.2926.vmw.x86_64.vib ########## [100%]
Unpacking glibc-2.5-34.2926.vmw.x86_64.vib ########## [100%]
Unpacking glibc-2.5-34.2926.vmw.i686.vib ########## [100%]
Installing glibc-common ########## [100%]
Installing glibc ########## [100%]
Installing glibc ########## [100%]
Installing vmware-esx-uwlibs ########## [100%]
Installing vmware-esx-esxupdate ########## [100%]
Cleaning up vmware-esx-esxupdate ########## [100%]
Cleaning up vmware-esx-uwlibs ########## [100%]
Cleaning up glibc-common ########## [100%]
Cleaning up glibc ########## [100%]
Cleaning up glibc ########## [100%]
Cette opération prendra un peu de temps, mais nettement moins que la suivante:
Host was not updated, no changes required.
Skipping bulletin ESX410-GA-esxupdate; it is installed or obsoleted.
Unpacking rpm_vmware-esx-likewise-ad-provider_4.1.0-0.0.2602.. ########## [100%]
Unpacking rpm_vmware-esx-srvrmgmt_4.1.0-0.0.260247@i386 ########## [100%]
Unpacking rpm_vmware-esx-drivers-char-tpm-tis_400.0.0.1.1-1v.. ########## [100%]
:
:
Cleaning up vmware-esx-nmp ########## [100%]
Cleaning up vmware-esx-drivers-net-tg3 ########## [100%]
Cleaning up nss_ldap ########## [100%]
Running [/usr/sbin/cim-install.sh]...
ok.
Running [/usr/sbin/vmkmod-install.sh]...
ok.
Running [esxcfg-boot -b]...
ok.
The update completed successfully, but the system needs to be rebooted for the changes to be effective.
Ensuite, un simple reboot pour finaliser l'installation
Et voila, votre ESX doit etre en version 4.1:
VMware ESX 4.1 (Kandinsky)
[ESX] Réduire la taille d'un vmdk
Dans mon métier, on doit parfois économiser de la place, mais sans rien effacer... Avant [VMWare] c'était impossible, maintenant, il existe un moyen... il s'agit du thin provisioning, en opposition au thick provisioning.
Thin ou Thick
Pour faire court, il est conseillé en VMWare de toujours alouer ses disques en mode thick (ce mode a l'avantage de faire des disques performants et rapides, mais a le désavantage (relatif) d'allouer toute la place demandée à la création du disque).
C'est aussi ce type de disque qui est créé par les outils P2V.
Alors oui, l'on peut débattre sur les raisons qui vous poussent à transformer des disques thick en thin provisioning, mais sur un ESXi de labo les performances sont rarement la priorité, et souvent vous n'avez pas la possibilité de "migrer" la machine d'un DataStore a un autre en changeant le type de provisioning.
J'ai dû, sur un ESXi qui supporte le réseau de formation, gagner de la place. En gros, j'avais besoin de récuper au minimim 50 GB) et il se trouve que sur mon seul datastore du labo, j'avais deux disques vmdk de 50 GB en mode thick (soit une allocation de 100GB), alors que l'un n'avait que 10 GB réellement utilisé, l'autre occupait 25 GB). Malheureusement pour moi, il ne me restait que 15 GB de libre sur le Datastore...
Marche a suivre
Soyez conscient que pour ces manœuvres, votre serveur ne sera pas disponible a vos utilisateurs.
Voyez la NOTE plus bas si vous devez maintenir un accès au serveur (ou que cette procédure prend trop de temps pour une fenêtre offline).
- Trouvez les bons disques
Vous devez parcourir vos Disques Virtuels dans vos machines pour voir le quel est le moins rempli.
Videz la poubelle, voyez si tout ce qui est sur le disque est réelement nécessaire (par exemple, j'avais 5 GB de temporaires et de fichiers d'installation inutile sur sur ce disque).
Arrêtez les services inutiles par exemple SQL, antivirus, etc... (Voir la NOTE)
 N'oubliez pas aussi de passer par la case défragmentation avant de continuer, cela peut sembler logique, mais j'avoue ne pas y avoir penser au début, et avoir perdu une bonne heure pour un résultat médiocre.
N'oubliez pas aussi de passer par la case défragmentation avant de continuer, cela peut sembler logique, mais j'avoue ne pas y avoir penser au début, et avoir perdu une bonne heure pour un résultat médiocre.

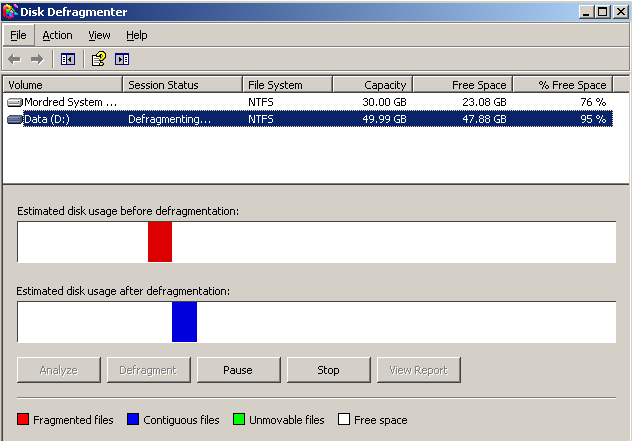
- Préparez le disque en utilisant les outils VMWare dans la machine Virtuel
Comme vous le savez surement, quand vous effacer un fichier, Windows n'efface pas réellement les données: le descripteur du fichier (son nom, le créateur, les dates connues [création, modification, accès], l'emplacement physique sur le disque, etc) est placé dans la poubelle, l'opération de vider la poubelle, efface ces descripteurs et marque les block de données comme libre... Windows sera libre de faire usage "au besoin" de ces blocks plus tard (bien plus tard en faite).
Donc l'outil VMWare va se charger de "mettre a zéro" ces blocks; en créant de gros fichiers de 2 GB nommé "wiper0", "wiper1", ... Ces fichiers vont permettre a l'ESX d'identifier les blocks comme étant réellement inutilisés.
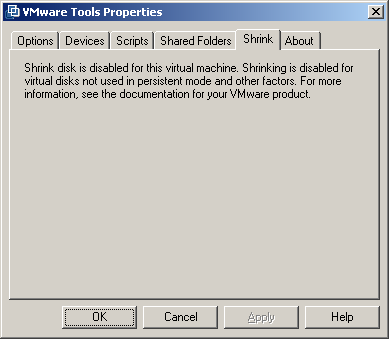
Si comme moi vous rencontrez ce type de message, dites vous que vous etes dans le bon, c'est juste que VMWare ne fait pas de shrink sur un disque en mode thin (c'est idiot mais bon)...
Normalement, votre disque est de base en thick, donc cette option sera active pour vous. Une fois que l'outil aura fait son œuvre, arrêter la machine Virtuelle.
NOTE Normalement vous devez avoir un downtime pour faire ces opérations "a l"aise"; mais il existe un moyen pour ne pas couper le serveur durant ces manœuvres, et donc maintenir l'accès; je n'ai pas tester cette méthode, donc je vous recommande la plus extrême prudence:
Arriver a ce point, vous devriez arreter votre serveur, mais vous pouvez aussi créer un snapshot du disque en question; tous les accès en écriture sur ce disque seront fait sur le snapshot et non sur le disque d'origine.
A la fin du clone - remplacement, il suffira d'effacer tout les snapshots de la machine; cela aura pour effet d'ajouter dans votre image finale, tout les changements effectués depuis le snapshot et de libérer ainsi la précieuse place.
- Ouvrez une session "root" via SSH sur un host ESX qui a accès au datastore
Rendez-vous en ligne de commande dans le bon dossier de stockage du serveur:
Dans cet exemple, j'utilise datastore1 comme volume VMFS et srv-mordred comme nom de machine virtuelle.
Avec une simple commande ls -l vous obtiendrez tout le contenu du dossier; mais en précisant un peu, il y a moyen de faire beaucoup mieux:
-rw------- 1 root root 502 Feb 3 10:38 srv-mordred.vmdk
-rw------- 1 root root 505 Feb 3 10:39 srv-mordred_1.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1-flat.vmdk
-rw------- 1 root root 32212254720 Feb 3 10:41 srv-mordred-flat.vmdk
L'on constate que les vmdk se répartissent en deux type des petits fichiers (moins de 5 KB, ici 502 et 506 bytes) et de très gros fichiers où est ajouté "-flat" au nom du disque, il se peut que vous ayez des fichiers avec "-XXXXX" ajouté dans le nom, ce sont les fichiers de snapshot, "-XXXXX-delta" contiendront donc logiquement les données de différence par rapport au disque d'origine.
NOTE: Vous pourrez noter que la console ne voit pas la taille réellement occupée par le disque, mais bien la taille maximum allouée a la création du disque (ici un disque de 30 GB et un de 50 GB), même si vous avez créer un disque "thin"; pour avoir cette taille réel, il vous faut allez dans le datastore browser.
- Créez un clone 'Thin' de votre disque
C'est ici que tout se joue, l'outil qui va tout faire pour vous (ou presque): "vmkfstools", ordonnons lui de faire un clone thin de votre disque:
l'option -i (input) spécifie le fichier source, l'option -d (destination) attends deux paramètres, le format du disque et son nom; dans ce cas ci,nous précision thin et le nom sera clair lui aussi.
Cloning disk 'srv-mordred_thin_1.vmdk'...
Clone: 100% done.
Une fois le clone fini, un petit 'ls' pour vérifier la présence du nouveau couple de fichiers:
-rw------- 1 root root 502 Feb 3 10:38 srv-mordred.vmdk
-rw------- 1 root root 505 Feb 3 10:39 srv-mordred_1.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1-flat.vmdk
-rw------- 1 root root 510 Feb 3 10:39 srv-mordred_1_thin.vmdk
-rw------- 1 root root 53687091200 Feb 3 10:41 srv-mordred_1_thin-flat.vmdk
-rw------- 1 root root 32212254720 Feb 3 10:41 srv-mordred-flat.vmdk
Vous pourriez être surpris que la taille du nouveau fichier flat est exactement la même que l'original thick; c'est du au fait que la console "voit" la taille des disques et non l'espace réellement occupé sur le stockage. Vous devrez allez dans le datastore browser pour y voir l'espace occupé.
- Remplacer le disque 'thick' avec le clone 'thin'
vous pouvez sans crainte effacer l'ancien 'thick' disque par le clone que vous venez de créer :
N'oubliez pas d'effacer le fichier de description "srv-mordred_1_thin.vmdk" qui n'a plus de raison d'être.
Vous pouvez bien sur toujours éditer le fichier de description pour y ajouter une ligne:
afin d'expliquer correctement a VSphere que c'est un disque thin et non thick.
EDIT: Connaitre la taille utilisée réelement et virtuellement
L'allocation de la taille se fait via le vsphere... Vous y verez la taille effectivement restante... a coté de la taille déjà "allouée"...
vous allez dans votre dossier /vmfs/volumes/VOLUMES
il existe une commande 'du -h' qui vous affichera l'usage disque réel de vos dossiers (pas l'alloué).
Un parametrage un peu barbare 'du --apparent-size -h' vous affichera l'usage disque virtuel (y compris les VMDK qui pointent vers des RDM)
[ESX] VMWare: théorie des stockages
Quant on travail avec VMWare on a parfois tendance a oublier les bases... Voila une piqûre de rappel plus que nécéssaire sur comment on stock des données sur un disque dur... et comment VMWare "émule" cela...
La machine Physique
Quand une application sur une machine physique veut écrire quelque chose sur un disque local, l'OS de la machine émet une requête d'écriture, cette requête va être traiter par le contrôleur de disques auquel est attaché le disque visé. Le HBA ou Contrôleur de Disque se charge de la gestion des disques (RAID, redondance, etc...)

La machine Virtuelle (VM)
Il en va de même pour une VM à la différence que les ordres traités par "contrôleur de disque" de la VM, vont être interceptés et redirigés vers le fichier VMDK qui "contient" les données du disque virtuel. Le serveur host VMWare va résoudre le chemin vers le datastore visé, et ce quelque soit la nature profonde du stockage. Sur un host avec stockage local, il s'agit d'initier un dialogue avec le HBA qui contrôle le disque dur en question et d'émettre une commande d'écriture d'un bloc donné à un endroit donné sur le disque.
![]()
Augmentation des Volumes et des disques
Quand le nombre de disques de stockage augmentent, et que nous débordons la capacité maximale du contrôleur SCSI, nous passons d'une version "direct attached" à une "mise en réseau" des disques, évidement le SCSI n'est pas capable directement de débordé son nombre de disque maximum, il faut passer par un appareil qui fera la jonction entre un grand nombre de disques physiques (plusieurs dizaines) et les serveurs qui ne peuvent voir qu'un faible nombre de disques (moins de 20).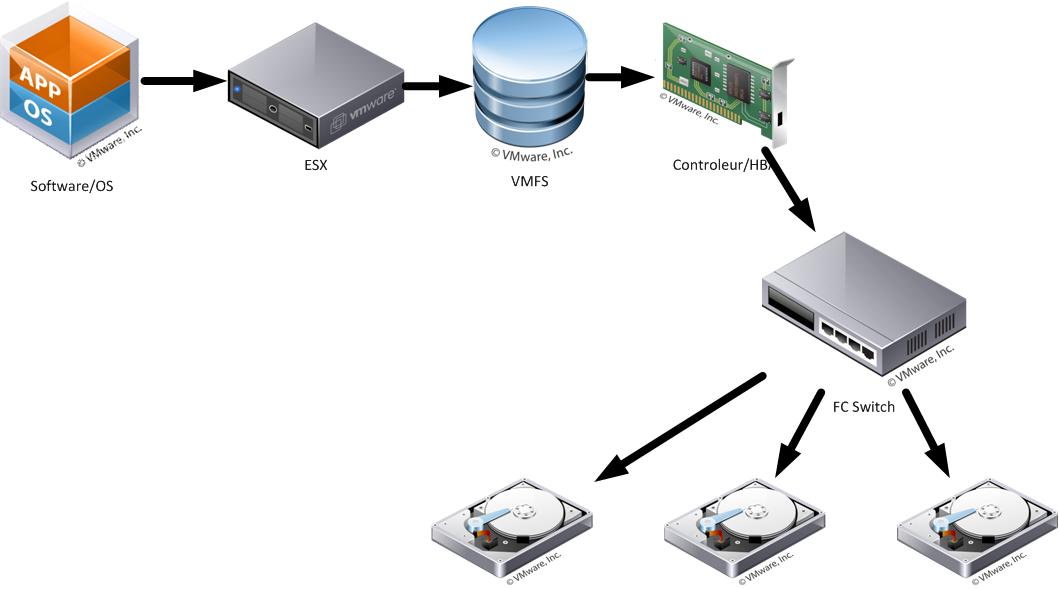
Les SANs
C'est l'idée de base des SAN qui offraient un grand nombre de disques montés et présentés comme un seul (ou quelques) disque(s) aux serveurs ESX.
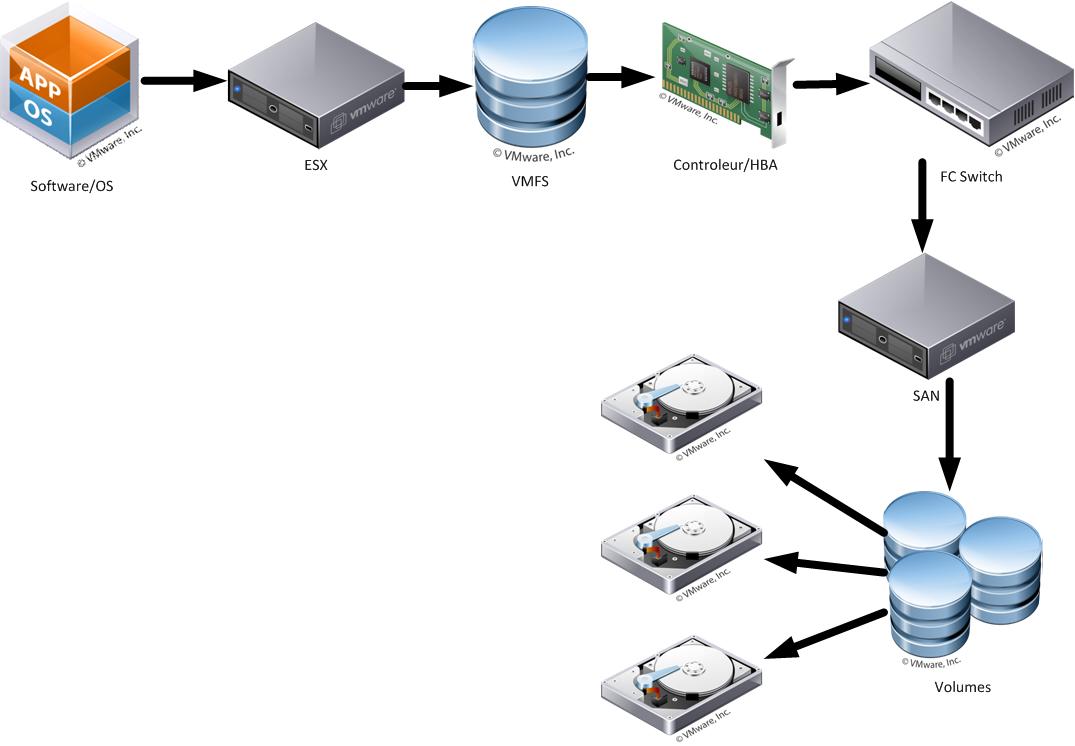
Cette suite d'événements parait évidente et simple, surtout avec des technologies éprouvées comme le FibreChannel (FC), mais n'oublions pas que VMWare écrit au final dans un fichier VMDK sur un filesystem VMFS, et que dans le cas d'un système de stockage distant a technique est la même que pour un disque local, sauf que les contrôleurs HBA doivent initier un dialogue avec un appareil distant, et que ce dialogue peut passer via divers appareils (switches fabric, controlleurs de SAN, etc) et dans ce cas déjà, beaucoup de problèmes externes peuvent se présenter.
Les NASs
Si au lieu d'utiliser un protocole "bloc", comme le FiberChannel, on doit écrire sur un NAS en iSCSI ou en NFS, les NAS n'écrivent pas directement sur des volumes, mais écrivent dans des fichiers locaux, au travers de l'OS du NAS:
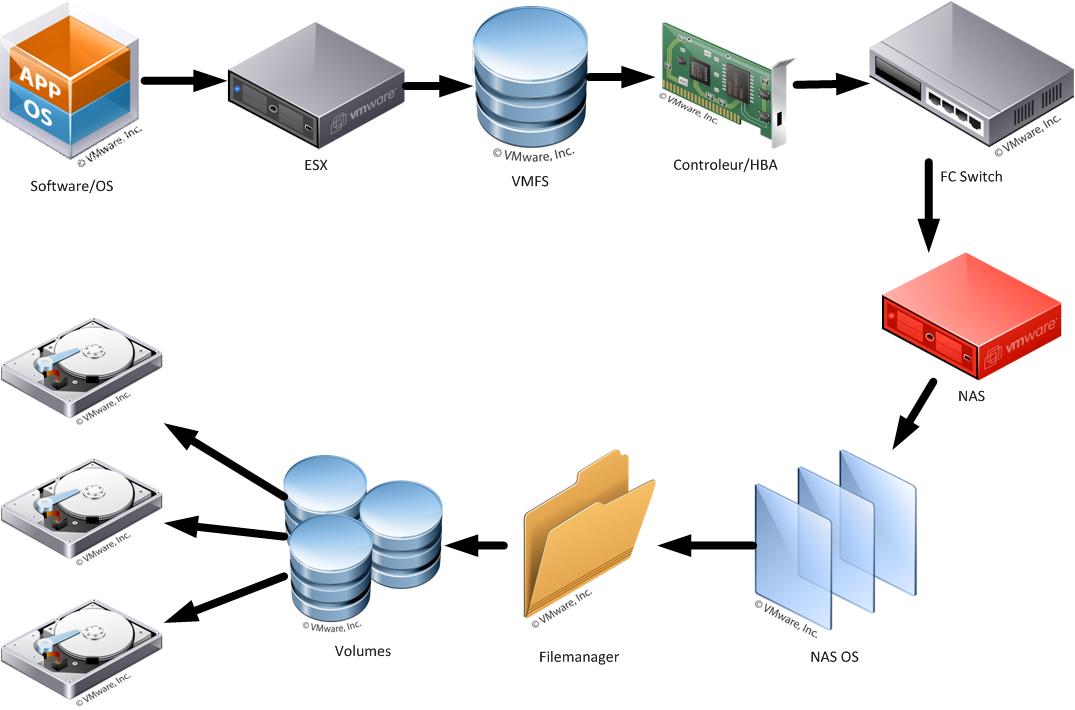
Ce système de fichiers NAS contient outre les données des fichiers également des métadonnées. Dans de nombreux cas, il est très important pour la stabilité du système que les métadonnées soient mise à jour de manière prudente et réfléchie, car si elle n'est pas, et il y a un réel risque de perte de données, en cas d'accident ou de panne de courant, qui pourrait rendre le système de fichiers instable, inutilisable, et même irrécupérable.
La Synchronisation
Quelque soit le type de stocakge (local, DirectAttached, NAS, SAN) il est important pour VMWare de s'assurer que toutes écritures a été faite correctement et réellement, donc en bon élèves, un ESX attendra la confirmation d'écriture avant de passer (réellement) à autre chose.
Le signal de synchronisation fournit a l'ESX l'assurance que les données qu'il a écrit sont écrites sur un disque et non "en transit". Ce type de signal dans un protocole "hardware" comme le FibreChannel ou le SCSI est assez facile a obtenir (puisque le contrôleur (ou le SAN) est responsable directement de la gestion des disques), mais plus délicats dans le cas d'un NAS du fait de la couche "software" qui ne sais pas toujours si les disques ont un "cache" d'écriture ou non.
ESX et les blocs de données
Un host VMWare considère toutes demandes d'écritures disques venant d'une VM comme "importantes" et prendra donc TOUTES les garanties pour l'écriture de celles-ci. Ce qui signifie qu'il attendra la réponse du système de stockage. Sur un SAN (ou tout autre système "bloc") cette réponse sera souvent immédiate (ou presque) mais sur un NAS, qui pour augmenter les performances, utilise souvent des caches et écrit sur les disques de manière asynchrone, cela peut prendre du temps.
Alors voilà le problème, ESX représente le disque dur de votre machine virtuelle dans un fichier VMDK. Cependant, il n'a vraiment aucune idée de ce que VM tente d'écrire sur le disque, et donc considère que toute écriture est précieuse. En d'autres termes, VMware écrit tout avec une demande de confirmation de synchronisation. Cela peut entraîner des ralentissements importants.
Sur un serveur avec stockage local, la solution typique à ce problème est d'utiliser un contrôleur RAID équipé de write back cache et d'une batterie de secours.
La même chose se produit sur des périphériques réseaux, VMware exige que toutes écritures soit faite sur un stockage stable,
Maintenant, il est important de comprendre que VMware veut être prudent avec vos données. Disons que votre VM met à jour certaines métadonnées du système de fichiers, par exemple, la table de blocs libres, car un certains nombres de fichiers ont été crées sur la VM.
- La VM écrit une mise à jour qui indique quels blocs ont été utilisés.
- ESXi envoie cette mise à jour vers le système de stockage NAS / SAN. Supposons que l’écriture est différée (pour des raisons de performances) et qu’à ce moment précis, une panne de courant (non secourue) survient.
Après redémarrage, le NAS montrera ces blocs comme libre et vide, la VM pourra écrire sur ces block (et donc remplacer le contenu des fichiers crées juste avant le crash).
Donc, la solution de VMware est de s'assurer que les écritures sont signalées comme synchronisé et de confier le problème du sous-système de stockage.
Sync or not Sync ?
Si dans les périphériques "blocs" (comme le SCSI ou le FiberChannel) la question ne se pose pas, elle se pose largement pour les périphériques "réseaux" et les protocoles IP.
En général, dans un protocole réseaux, vous avez le choix d’activé la synchronisation ou non, c'est souvent une question de cout/performances/risques qui vous permettra de décider.
- NFS, par défaut, activera la synchronisation en écriture à la demande des ESX. C'est pourquoi il est lent. Vous pouvez améliorer les performances avec un cache Front en SSD.
- iSCSI, par défaut, n’a pas synchronisation. En tant que tel, il apparaît souvent comme beaucoup plus rapide, et donc un bien meilleur choix que NFS, cependant, attention là aussi aux pertes de données. On peut activer la synchronisation sur les données iSCSI, mais dès lors les performances seront en baise.
[Workstation] Monter des VMDK sous Windows 7 64bits (même Ext2 et 3)
Rhhaaaaa, la version Workstation 9 ne supporte que des cartes réseaux à 100Mbps, et pour transférer de gros volumes c'est LENT! Pas de panique, il existe une solution simple, monter le volume sur l'OS host (ici Windows 7 64bits).
C'est simple pour des disques VMDK en NTFS ou en FAT (32), mais pour les disques en Ext2/3 vous pouvez allez vous brosser... mais j'ai la solution.
Monter un volume (NTFS/FAT(32))
Pour monter un Volume VMDK sur le host (Windows) c'est assez simple:
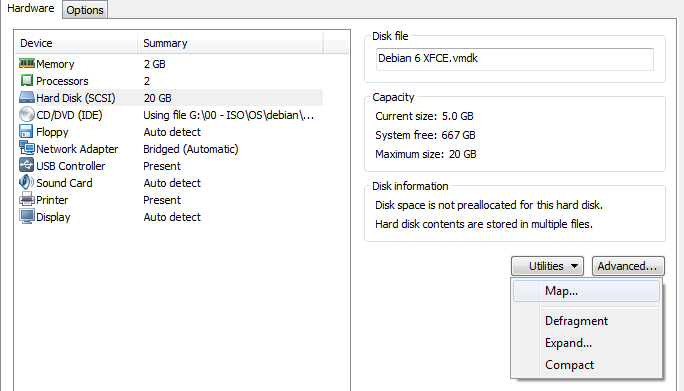
Puis de remplir les paramêtres:
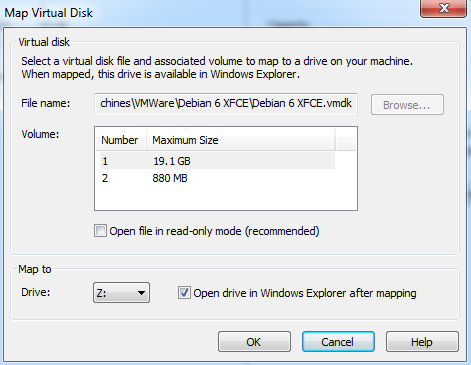
Pour du NTFS/FAT aucun soucis, pour du EXT2/3, vous aurez Windows qui vous demandera a formater la partition... horreur :D
La Solution
Il suffit d'installer le drivers qui va bien: ext2fsd
Une fois ce drivers installer, votre partition sera visible comme une partition Windows classique dans votre explorer...