Tutoriaux: back to root....
Retour aux sources... vive le DOS et les PC d'avant 2000...
En mettant de l'ordre dans mes disques durs, j'ai retrouvé quelques très vieux codes source sous MSDOS, en PASCAL, en C, en Assembleur x86. Je me suis surpris à tenter de les faire tourner.
J’ai donc installé une VM en MSDOS, mais les performances et le résultat désastreux de certains codes m’ont fait penser que, ce n’était pas la bonne approche, de plus, la VM n’offrait pas de support pour la moindre carte son compatible SB16 ou Gravis Ultra Sound…
N’ayant plus de machine 486 sous la main avec un bus ISA pour y coller les cartes son nommées ci-dessus, il m’était impossible de faire fonctionner ces codes sources sur du vrai hardware et les VM ne fonctionnaient pas non plus… DOSBOX était une possibilité, mais la compatibilité de certains composants n’était pas là non plus… notament dès que l'on veut exploiter des fonctions très spécifiques du hardware...
Quand on voit ce qui est fait pour des machines de la même époque ou plus ancienne, je trouvais cela dommage de voir que l’ancêtre de notre PC actuelle n’était pas « préservé » avec un bon émulateur… C’est du moins ce que je pensais jusqu’à ce que je découvre DOSBox-X, un fork de DOSBox, mais en mieux… Du coup, j’ai pu faire tourner mon vieux code :D
J'aouterais qu'il existe aussi un excelent emulateur hardware : PCem qui n'offre pas toujours toutes les options de configurations (notament pour la GUS) mais qui émule réelement un PC, il faut dès lors se procurer le/les BIOS des PC que l'on veut émuler.
L'emulation hardware est quasi parfaite, mais j'avoue que la gestions des "hot-keys" est pénible...
Du coup, j’ai ressorti mes vieux livres et j’ai recommencé à jouer (mais avec beaucoup plus d’expérience…) pour contrôler ce vénérable ordinateur.
Pour ces tutoriaux, vous aurez besoin de:
- DosBox-X (http://dosbox-x.com/)
- Borland C 3.1 (see this article or this)
- PCem (https://pcem-emulator.co.uk/)
Un peu de litérature:
- Borland C++ Library reference (read here)
- Borland C++ User's Guide (read here)
- Borland C++ programmer's Guide (read here)
- PC Underground (link)
Références:
- PhatCod.net (link)
- http://stanislavs.org/helppc/ (link)
- DosBox-X : configuration manual (here)
Outils utiles:
Tutoriaux: VGA Avancée - DAC - Part 1
Le DAC
Le moniteur doit commander l'intensité des trois faisceaux d'électrons (rouge, vert, bleu) qui vont permettre l'affichage des différentes couleurs. Cette intensité est une valeur analogique qui n’est pas présente au coeur d’une carte VGA (qui traite les intensités de façon numérique).
Le DAC possède une palette qui, à un index de couleur (choisi parmi 256), associe les proportions des trois signaux de base rouge, vert et bleu. Ces proportions peuvent être modifiées par le programmeur pour chacune des 256 couleurs. Le DAC se charge alors de traduire les proportions associées à une couleur en signaux analogiques parfaitement compréhensibles par le moniteur.
La modification des valeurs de la table se fait de maniere assez simple en spécifiant l’index de couleur a modifié sur le port 0x3C8 (PEL Address), et en injectant 3 octets (un pour chaque intensité) sur le port 0x3C9 (DAC), le DAC se chargeant de placer les valeurs dans les registres ad-hoc.
mov dx,0x3c8 ; DAC PEL address
out dx,al
mov dx,0x3c9 ; DAC
mov al,db_Red
out dx,al ; write Red level for colorID
mov al,db_Green
out dx,al ; write Green level for colorID
mov al,db_Blue
out dx,al ; write Blue level for colorID
Raster
A quoi cela peut il servir ? A créer un dégradé sur la couleur de fond, dans n’importe quel mode « couleur » de la carte VGA ; meme en mode texte... ca peut servir par exemple pour "enrichir" un menu de configuration...
#include "conio.h"
typedef unsigned char BYTE;
typedef unsigned int WORD;
// copper_maxrow is a parameter to avoid copper/raster to turn forever
// copper_error must be set to 0 to run
int copper_maxrow = 400;
BYTE copper_error = 0;
// this constant define the raster precistion (for percentage calculation)
#define PRECIS 8
/*
Draw a raster with RGB(sr,sg,sb) -> RGB(dr,dg,db) in « count » lines
0 mean 0, 255 mean 100 %
*/
void DrawRaster(BYTE st_red, BYTE st_green, BYTE st_blue, BYTE dt_red, BYTE dt_green, BYTE dt_blue, WORD count )
{
int step_percent;
char step_red, step_green, step_blue;
// Since the VGA color range is only 6 bit, we divide by 4 the byte
st_red = st_red>>2;
st_green = st_green>>2;
st_blue = st_blue>>2;
dt_red = dt_red>>2;
dt_green = dt_green>>2;
dt_blue = dt_blue>>2;
asm {
xor ah,ah // calculate Red Stepping
mov al,dt_red // endcolor - startcolor
mov bl,st_red
sub al,bl
mov step_red,al // red delta = endredcolorlevel - startredcolorlevel
xor ah,ah
mov al,dt_green // calculate Green Stepping
mov bl,st_green
sub al,bl
mov step_green,al
xor ah,ah
mov al,dt_blue // calculate Blue Stepping
mov bl,st_blue
sub al,bl
mov step_blue,al
xor cx,cx // cx = 0 (current line = 0)
mov dx,0x3DA } // wait for stable know line count (0)
w1: asm {
in al,dx
test al,0x08
jne w1 }
w2: asm {
in al,dx
test al,0x08
je w2 }
start:asm {
cli // protection overscan : Current line > max
mov bl,0x05 // error 5 : overload
cmp cx,copper_maxrow // line counter over max ?
jae eocl
cmp cx,count // raster completed ?
jae clean_eocl
inc cx // current line ++
mov dx,0x3da } // read input state
in_retrace:asm {
in al,dx // test if we are redrawing
test al,1
jne in_retrace }
in_display:asm {
in al,dx
test al,1 // wait for hbl (horizontal return)
je in_display } // new line
set_color: asm {
xor dx,dx
mov ax,cx
shl ax,PRECIS
mov bx,count
div bx
mov bx,ax // BX = percent
xor al,al // set color 0 (background)
mov dx,0x3c8
out dx,al
inc dx // mov dx,0x3c9 optimisation
xor ax,ax
mov al,step_red // get RED level
mul bl
shr ax,PRECIS // reduce precision
add al,st_red
out dx,al // set RED to dac
xor ax,ax
mov al,step_green // get GREEN level
mul bl
shr ax,PRECIS
add al,st_green
out dx,al // set GREEN to dac
xor ax,ax
mov al,step_blue // get BLUE level
mul bl
shr ax,PRECIS
add al,st_blue
out dx,al // set BLUE to dac
jmp start } // get next operand
clean_eocl: asm {
xor bl,bl // clear error operand
}
eocl:asm {
xor al,al // normally we should restore whole DAC's status
mov dx,0x3c8 // but we only reset color 0 to black
out dx,al
inc dx
out dx,al // turn to RGB 0,0,0
out dx,al
out dx,al
sti
mov copper_error, bl } // set error (if any)
}
void main()
{
unsigned char running=1;
textmode(3);
clrscr();
while (running)
{
running=(copper_error?0:1);
if (kbhit())
{
running=0;
}
// do some stuffs
printf("T h i s I s T h e T e s t");
DrawRaster(0x00, 0x00, 0x00,0xFF, 0x1F, 0xF0,200);
}
}
To be continued...
Tutoriaux: VGA Avancée - DAC - Part 2
Les CopperList
Sur mon Amiga, il y avait un truc qui était terrible: le processus "Copper"... c'est une partie du "processeur" graphique de l'Amiga, en modifiant ses registres, on changeait la résolution, les methode d'affichage, et meme le nombre de bits d'affichage...
Mais cela pouvait bien plus, car on pouvait lui faire executé des instructions en meme temps qu'il "dessinait" l'image sur l'écran.
Une Copperlist, c'est tout simplement la liste des instructions que le Copper doit exécuter lors d'un balayage écran, ce qui correspond au trajet du faiseau du coin en haut à gauche (0,0) au coin en bas à droite (maxx,maxy).
Malheureusement la carte VGA ne dispose pas de ce type de processeur, même si elle dispose de pas mal de "petits" controleurs simplifiés (notament un motorola CRTC 6845), il n'existe rien d'aussi puissant sur PC, il faudra donc que le x86 se charge de la tache si l'on désire arriver à émuller une copperlist (le but de cet article).
Les instructions du CopperList
Le copper ne comprends que 3 instructions, mais c'est amplement suffisant pour "controler" le faiseau lumineux.
Je ne vais pas entrer trop dans les détails techniques de l'Amiga, ce n'est pas le but de l'article, mais il est important de comprendre le fonctionnement de la copperlist de ce dernier si nous voulons arriver à faire quelque chose sur le PC qui soit "un peu spéciale".
WAIT
Cette instruction permet d'attendre une position précise à l'écran; toutefois cette précision est "réduite" pour ce qui est de la position horizontale. Cette restriction horizontale fait que l'on peut seulement "pointer" un modulo de 4 pixels.
Les raisons de ce modulo sont assez évidentes: aller au pixel près aurait demandé un trop grande puissance CPU, ce qui à l'époque n'était pas possible, et aurait également demandé plus de bytes dans l'instruction.
SKIP
Similaire à wait, mais avec un bit de différence...
MOVE
Cette instruction permet de charger un registre du copper avec une valeur... Comme je l'ai dis dans l'introduction, les registres du copper etait nombreux, et controlaient avec précision ce qui était afficher.
Notre CopperList
Pour notre copperlist, je vais garder le principe de peu d'instructions, mais je ne vais pas optimiser ces listes d'instruction pour le moment.
Vu que tout devra être traiter par le x86 et qu'il faut garder du temps CPU, je ne vais pas essayer de me "caler" autrement que sur la verticale, l'horizontale serait sans doute possible, mais couterait très certainement 100% du CPU (voir plus).
WAIT: 0x10
Cette instruction va faire "compter" notre routine le nombre de "retour de balayage", aucune autre instruction de notre programme ne sera lue avant que le compteur de ligne n'ait atteint la valeur précisée. Les "interruptions" sont possible, ce qui fait que le "compteur" peut rater un ou plusieurs retour de balayage.
Dès que le compteur atteints (ou dépasse) la valeur, le copperlist se remet à lire les instructions du programme.
| Byte 0 | Byte 1 | Byte 2 |
| 0x10 | LineH | LineL |
Une protection "overflow" existe si le compteur dépasse plus de 400 comptages. Cette valeur est précisée dans la variables copper_maxrow du programme. Dans ce cas, une erreur sera émise et notre fonction cessera de s'executer, on peut connaitre l'état du copperlist en regardant la variable copper_error.
SetColor: 0x20
Cette instruction va charger le DAC avec 4 octets, le 1er étant l'index de la couleur a changer, suivit des valeur de rouge, vert, bleu. Aaprès l'écriture dans le DAC, l'instruction suivante du copperlist est lue.
| Byte 0 | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
| 0x20 | Color | Red | Green | Blue |
On n'oublie pas qu'une carte VGA ne peux choisir les intensités de rouge, vert, bleu que sur une plage de valeur de 0 à 63.
Aucun controle n'est fait sur les paramètres, si ceux-ci dépassent 63 par exemple, la valeur sera transmise au DAC directement, les réactions de ce derniers ne sont pas connues, aucune erreur ne sera détectée.
EOC: 0xFF
Cette instruction fini l'execution du copperlist, la couleur 0 (fond d'écran) est forcée à (0,0,0).
| Byte 0 |
| 0XFF |
Le code
#include "dos.h"
#include "conio.h"
typedef unsigned char BYTE;
typedef unsigned int WORD;
// copper_maxrow is a parameter to avoid copper/raster to turn forever
// copper_error must be set to 0 to run
int copper_maxrow = 400;
BYTE copper_error = 0;
#define PRECIS 8
BYTE copperlist[] =
{
0x10, 0x00, 0x64, // waitLine 100
0x20, 0x00, 0x0D, 0x00, 0x0b, // setColor 0x00 0x0d,0x00,0x0b
0x10, 0x00, 0x96, // waitLine 150
0x20, 0x00, 0x2F, 0x12, 0x17, // setColor 0x00 0x2f,0x12,0x17
0x10, 0x00, 0xFA, // waitLine 255
0x20, 0x00, 0x09, 0x0F, 0x34, // setColor 0x00 0x09,0x0f,0x34
0xFF // EOC
};
void DrawCopperList(char *copperlist)
{
if (copper_error!=0)
return;
asm {
push ds
push si
lds si,copperlist
xor cx,cx // reset cx
xor bx,bx
mov dx,0x3DA } // wait for stable know pos (0)
w1: asm {
in al,dx
test al,0x08
jne w1 }
w2: asm {
in al,dx
test al,0x08
je w2 }
start:asm {
// protection
mov al,0x05 // error 1
cmp cx,copper_maxrow // line counter copper > max ?
jae eocl
lodsb // get copper list operand
cmp al,0xFF // eocl ?
je clean_eocl
cmp al,0x10 // wait ?
je wait_line
cmp al,0x20 // set color ?
je set_color
mov al,0xFF // unknown command
jmp eocl }
// ------------------------------------- Wait Line
wait_line:asm {
lodsw
mov bh,al
mov bl,ah
mov bh,al }
wait_next: asm {
inc cx // cx = cx+1
cmp cx,bx // current line >= wait_line ?
ja start } // YES : next operand please
wait_hbl:asm {
mov dx,0x3da } // read input state
in_retrace:asm {
in al,dx // test if we are redrawing
test al,1
jne in_retrace }
in_display:asm {
in al,dx
test al,1 // wait for hbl (horizontal return)
je in_display
jmp wait_next } // new line
// ------------------------------------- Set Color
set_color: asm {
cli
lodsb // get Color
mov dx,0x3c8
out dx,al // select color index
mov dx,0x3c9
lodsb // get RED level
out dx,al // set RED to dac
lodsb // get GREEN level
out dx,al // set GREEN to dac
lodsb // get BLUE level
out dx,al // set BLUE to dac
jmp start } // get next operand
// ------------------------------------- End CopperList
clean_eocl: asm {
xor al,al } // clear error operand
eocl:asm {
sti
pop si
pop ds
mov copper_error, al // set error (if any)
xor al,al // normally we should restore whole DAC's status
mov dx,0x3c8 // but we only reset color 0 to black
out dx,al
inc dx
out dx,al // turn to RGB 0,0,0
out dx,al
out dx,al }
}
void main()
{
unsigned char running=1;
textmode(3);
clrscr();
while (running)
{
running=(copper_error?0:1);
if (kbhit())
{
running=0;
}
// do some stuffs
printf("T h i s I s T h e T e s t\n");
DrawCopperList(copperlist);
}
printf("\n error: %i\n",copper_error);
}
Littératures:
Tutoriaux: VGA Avancée - DAC - Part 3
CopperList avancée
Dans nos deux derniers articles, nous avons appris à faire des dégradés et ensuite a programmer un changement de couleur suivant l'index de la ligne en cours. Maintenant il faut mixer les deux.
Comme je l'ai dit dans un article précédent, la carte VGA n'est pas aussi performante que un processeur dédié comme en disposait l'amiga (voir meme le C64 dans une moindre mesure).
Nous allons donc re-définir nos instructions et en ajouter une nouvelle.
Instruction CopperList
Nous allons corrigé un problème qui peut se présenter avec certains chipset VGA, la limite des intensitée qui varie de 0 à 63. Pour éviter les ennuis, nous allons tout simplement ramener les intensité de notre copperlist à 6 bits (via un shr).
Wait: 0x10
Aucune modification n'est apportée a cette instruction.
SetColor: 0x20
Cette instruction est modifiée dans son comportement, les intensitée de rouge, vert et bleu sont divisée par 4 avant d'être envoyées au DAC.
GradiantTo: 0x30
Cette instruction prends les valeurs du dernier "SetColor" (y compris la couleur) pour faire varier les intensitée jusqu'aux nouvelles valeurs paramètres, et ce depuis la ligne courant jusqu'à la ligne cible.
| Byte 0 | Byte 1 | Byte 2 |
Byte 3 | Byte 4 |
Byte 5 |
| 0x30 | LineH | LineL | Red | Green | Blue |
Les bytes "LineH" et "LineL" sont les octets de poids fort et faible du mot qui défini la ligne "cible", celle-ci DOIT être inférieur à copper_maxrow, sans quoi l'excécution des copper s'arretent avec un code d'erreur.
EOC: 0xFF
Cette instruction n'est pas modifiée.
Le Code
#include "conio.h"
typedef unsigned char BYTE;
typedef unsigned int WORD;
// copper_maxrow is a parameter to avoid copper/raster to turn forever
// copper_error must be set to 0 to run
int copper_maxrow = 400;
BYTE copper_error = 0;
#define PRECIS 8
BYTE copperlistv2[] =
{
0x20, 0x00, 0x00, 0x00, 0x00, // setColor 0x00 0x00,0x00,0x00 : Black
0x30, 0x00, 0x32, 0xFF, 0xFF, 0x00, // GradiantTo 0x32 0xFF,0xFF,0x00 : Yellow
0x30, 0x00, 0x64, 0xFF, 0x00, 0x00, // GradiantTo 0x64 0x09,0x0f,0x34 : Red
0x30, 0x00, 0x96, 0x00, 0x00, 0x00, // GradiantTo 0x96 0x00,0x00,0x00 : Black
0x30, 0x00, 0xC8, 0xFF, 0xFF, 0x00, // GradiantTo 0x32 0xFF,0xFF,0x00 : Yellow
0x30, 0x00, 0xFA, 0xFF, 0x00, 0x00, // GradiantTo 0x64 0x09,0x0f,0x34 : Red
0x30, 0x01, 0x2C, 0x00, 0x00, 0x00, // GradiantTo 0x96 0x00,0x00,0x00 : Black
0xFF // EOC
};
void DrawCopperListv2(char *copperlist)
{
BYTE color=0;
BYTE red_prec=0, green_prec=0, blue_prec=0; // color set or starting of gradient
BYTE red_step=0, green_step=0, blue_step=0; // steps (end color - start color)
BYTE red_end=0, green_end=0, blue_end=0; // end color
WORD line_end=0, line_start=0; // line end line start
WORD line_delta=0; // delta between end and start
if (copper_error!=0)
return;
asm {
push ds
push si
lds si,copperlist
xor cx,cx // reset cx : line counter
xor bx,bx
mov dx,0x3DA } // wait for stable know pos (0)
w1: asm {
in al,dx
test al,0x08
jne w1 }
w2: asm {
in al,dx
test al,0x08
je w2 }
start:asm { // protection
mov al,0x05 // error 1
cmp cx,copper_maxrow // line counter copper > max ?
jb start2 // go
jmp eocl } // exit
start2: asm {
lodsb // load copper list operand
cmp al,0xFF // eocl ?
jne start3
xor al,al
jmp eocl }
start3: asm {
cmp al,0x10 // wait ?
jne start4
jmp wait_line }
start4:asm {
cmp al,0x20 // setcolor ?
jne start5
jmp set_color }
start5:asm {
cmp al,0x30 // gradient ?
je gradient
mov al,0xFF // unknown command
jmp eocl }
// ------------------------------------- GRADIENT
gradient: asm {
mov line_start,cx // preserve line start
lodsw
mov bh,al // reverse endian
mov bl,ah
mov line_end,bx // preserve line end
// calculate the number of line between line_start and line_end
sub bx,cx
mov line_delta,bx // pct_max = line count between line_start and end
lodsb // load red_end
shr al,2 // reduce to 6 bits only
mov red_end,al // preserve red target
mov ah,al
mov bl,red_prec // bl = red start
sub al,bl // end - start
mov red_step,al // calculate Red Stepping
mov red_prec,ah //
lodsb // load green_end
shr al,2
mov green_end,al
mov ah,al
mov bl,green_prec // get green start
sub al,bl
mov green_step,al // calculate green stepping
mov green_prec,ah
lodsb // load blue_end
shr al,2
mov blue_end,al
mov ah,al
mov bl,blue_prec
sub al,bl
mov blue_step,al
mov blue_prec,ah } // calculate Blue Stepping
gr_start: asm {
inc cx // cx = cx+1
cmp cx,line_end // gradient complet ?
jb gradient_hbl
jmp start } // next operant
gradient_hbl:asm {
mov dx,0x3da } // read input state
gr_in_retrace:asm {
in al,dx // test if we are redrawing
test al,1
jne gr_in_retrace }
gr_in_display:asm {
in al,dx
test al,1 // wait for hbl (horizontal return)
je gr_in_display
mov ax,cx
sub ax,line_start // pct_current(ax) = currentline(cx) - line_start
mov bx,line_delta // bx = line_start - line_end
xor dx,dx
shl ax,PRECIS // increase precision
div bx // pct_current / pct_max
mov bx,ax // bx = percentage 0..100
cli
mov al,color
mov dx,0x3c8
out dx,al // select color index
inc dx
xor ax,ax
mov al,red_step
imul bl // must be signed multiplication
shr ax,PRECIS
add al,red_prec
out dx,al // set RED to dac
mov red_end,al
xor ax,ax
mov al,green_step
imul bl // must be signed multiplication
shr ax,PRECIS
add al,green_prec
out dx,al // set GREEN to dac
mov green_end,al
xor ax,ax
mov al,blue_step
imul bl // must be signed multiplication
shr ax,PRECIS
add al,blue_prec
out dx,al // set BLUE to dac
mov blue_end,al
sti
jmp gr_start } // new line
// ------------------------------------- WAIT
wait_line:asm {
lodsw
mov bh,al // swap byte endian encoding craps
mov bl,ah // bx = line word
mov dx,0x3da } // input state
wait_next: asm {
inc cx // cx = cx+1
cmp cx,bx // current line >= wait_line ?
jae wait_end } // YES : next operand please
in_retrace:asm {
in al,dx // read input state, test if we are redrawing
test al,1
jne in_retrace }
in_display:asm {
in al,dx
test al,1 // wait for hbl (horizontal return)
je in_display
jmp wait_next } // new line
wait_end:asm {
jmp start }
// ------------------------------------- SETCOLOR
set_color: asm {
cli
lodsb // get color index
mov color,al
mov dx,0x3c8
out dx,al // select color index
inc dx // mov dx,0x3c9
lodsb // get RED level
shr al,2
mov red_prec,al
out dx,al // set RED to dac
lodsb // get GREEN level
shr al,2
mov green_prec,al
out dx,al // set GREEN to dac
lodsb // get BLUE level
shr al,2
mov blue_prec,al
out dx,al // set BLUE to dac
sti
jmp start } // get next operand
eocl:asm {
sti
pop si
pop ds
mov copper_error, al // set error (if any)
xor al,al // normally we should restore whole DAC's status
mov dx,0x3c8 // but we only reset color 0 to black
out dx,al
inc dx
out dx,al // turn to RGB 0,0,0
out dx,al
out dx,al }
}
void main()
{
unsigned char running=1;
textmode(3);
clrscr();
while (running)
{
running=(copper_error?0:1);
if (kbhit())
{
running=0;
}
// do some stuffs
printf("T h i s I s T h e T e s t\n");
DrawCopperListv2(copperlistv2);
}
printf("\n error: %i\n",copper_error);
}
Commentaire sur les sources
A cause des limitations du x86 concernant les jump conditionnels (near) il a fallut mettre en place un structure de type switch case.
Le build-in assembler de borland C++ n'est pas capable de faire de sauts conditionnel au delà d'un delta de -126 +127; car l'oppérande n'est que de 2 octets, pour contourner ce problème il aurait fallut écrire le code assembleur .386 dans un fichier .asm et ensuite le linker au code C, ce qui aurait permis de réduire la "boucle" comme ceci:
cmp cx,copper_maxrow // line counter copper > max ?
jae eocl // exit
lodsb // load copper list operand
cmp al,0xFF // eocl ?
je eocl
cmp al,0x10 // wait ?
je wait_line
cmp al,0x20 // setcolor ?
je set_color
cmp al,0x30 // gradient ?
je gradient
jmp eocl // unknown command
Ce qui se révèle plus simple et plus rapide (pas de re-fetch), mais dans le cadre de ce tuto cela n'a pas grande importance.
Source Code asm
jumps
locals
.386
PRECIS EQU 8
CODESEG
; public variables
_copper_error db 0 ; error reporting
_copper_maxrow dw 400 ; max linescan
public _copper_error
public _copper_maxrow
; private variables
;color db 0 ; color set or starting of gradient
;red_prec db 0
;green_prec db 0
;blue_prec db 0
;red_step db 0 ; steps (end color - start color)
;green_step db 0
;blue_step db 0
;red_end db 0 ; end color
;green_end db 0
;blue_end db 0
;line_end dw 0 ; line end line start
;line_start dw 0
;line_delta dw 0 ; delta between end and start
public _DrawCopperList
_DrawCopperList PROC C FAR
ARG CopperList:DWORD
local color:byte
local red_prec:byte, green_prec:byte, blue_prec:byte
local red_step:byte, green_step:byte, blue_step:byte
local red_end:byte , green_end:byte , blue_end:byte
local line_end: word, line_start: word, line_delta: word
push ds
push si
lds si,copperlist
cmp cs:_copper_error,0
jne clean_eocl
xor ecx,ecx ; reset cx : line counter
xor ebx,ebx
mov dx,03DAh ; wait for stable know pos (0)
w1: in al,dx
test al,08h
jne w1
w2: in al,dx
test al,08h
je w2
start: mov al,01h ; error 1
cmp cx,CS:_copper_maxrow ; line counter copper > max ?
jae eocl ; exit
lodsb ; load copper list operand
cmp al,0FFh ; eocl ?
je clean_eocl
cmp al,010h ; wait ?
je wait_line
cmp al,020h ; setcolor ?
je set_color
cmp al,030h ; gradient ?
je gradient
mov al,002h ; unknown command
jmp eocl
; ------------------------------------- GRADIENT
gradient:
mov line_start,cx ; preserve line start
lodsw
mov bh,al ; reverse endian
mov bl,ah
mov line_end,bx ; preserve line end
; calculate the number of line between line_start and line_end
sub bx,cx
mov line_delta,bx ; pct_max = line count between line_start and end
lodsb ; load red_end
shr al,2 ; reduce to 6 bits only
mov red_end,al ; preserve red target
mov ah,al
mov bl,red_prec ; bl = red start
sub al,bl ; end - start
mov red_step,al ; calculate Red Stepping
mov red_prec,ah
lodsb ; load green_end
shr al,2
mov green_end,al
mov ah,al
mov bl,green_prec ; get green start
sub al,bl
mov green_step,al ; calculate green stepping
mov green_prec,ah
lodsb ; load blue_end
shr al,2
mov blue_end,al
mov ah,al
mov bl,blue_prec
sub al,bl
mov blue_step,al
mov blue_prec,ah ; calculate Blue Stepping
gr_start:
inc cx ; cx = cx+1
cmp cx,line_end ; gradient complet ?
jb gradient_hbl
jmp start ; next operant
gradient_hbl:
mov dx,03DAh ; read input state
gr_in_retrace:
in al,dx ; test if we are redrawing
test al,1
jne gr_in_retrace
gr_in_display:
in al,dx
test al,1 ; wait for hbl (horizontal return)
je gr_in_display
xor eax,eax
mov ax,cx
sub ax,line_start ; pct_current(ax) = currentline(cx) - line_start
mov bx,line_delta ; bx = line_start - line_end
xor dx,dx
shl eax,PRECIS ; increase precision
div bx ; pct_current / pct_max
mov bx,ax ; bx = percentage 0..100
cli
mov al,color
mov dx,03C8h
out dx,al ; select color index
inc dx
xor eax,eax
mov al,red_step
imul bl ; must be signed multiplication
shr ax,PRECIS
add al,red_prec
out dx,al ; set RED to dac
mov red_end,al
xor ax,ax
mov al,green_step
imul bl ; must be signed multiplication
shr ax,PRECIS
add al,green_prec
out dx,al ; set GREEN to dac
mov green_end,al
xor ax,ax
mov al,blue_step
imul bl ; must be signed multiplication
shr ax,PRECIS
add al,blue_prec
out dx,al ; set BLUE to dac
mov blue_end,al
sti
jmp gr_start ; new line
; ------------------------------------- WAIT
wait_line:
lodsw
mov bh,al ; swap byte endian encoding craps
mov bl,ah ; bx = line word
mov dx,03DAh ; input state
wait_next:
inc cx ; cx = cx+1
cmp cx,bx ; current line >= wait_line ?
jae wait_end ; YES : next operand please
in_retrace:
in al,dx ; read input state, test if we are redrawing
test al,1
jne in_retrace
in_display:
in al,dx
test al,1 ; wait for hbl (horizontal return)
je in_display
jmp wait_next ; new line
wait_end:
jmp start
; ------------------------------------- SETCOLOR
set_color:
cli
lodsb ; get color index
mov color,al
mov dx,03C8h
out dx,al ; select color index
inc dx ; mov dx,0x3c9
lodsb ; get RED level
shr al,2
mov red_prec,al
out dx,al ; set RED to dac
lodsb ; get GREEN level
shr al,2
mov green_prec,al
out dx,al ; set GREEN to dac
lodsb ; get BLUE level
shr al,2
mov blue_prec,al
out dx,al ; set BLUE to dac
sti
jmp start ; get next operand
clean_eocl:
xor al,al
eocl:
mov _copper_error, al ; set error (if any)
pop si
pop ds
xor al,al ; normally we should restore whole DAC's status
mov dx,03C8h ; but we only reset color 0 to black
out dx,al
inc dx
out dx,al ; turn to RGB 0,0,0
out dx,al
out dx,al
ret
_DrawCopperList endp
END
le header .h
#define __COPPERL_H__
extern unsigned char copper_error; // error reporting
extern unsigned int copper_maxrow; // max linescan
extern void DrawCopperList(unsigned char *CopperList);
#endif
Littératures:
TBC
Tutoriaux : Future Crew Unreal Reverse Engineering - Part 1
Intro
La démo "Unreal" de Future Crew (http://www.pouet.net/prod.php?which=1274) est l'une des premières demos sur PC qui à eut (à l'époque) un effet "Woooowwww" massif.
Cette démo et surtout la seconde a permis a ce groupe de devenir légendaire... Pour le 20eme anniversaire de "Second Reality" en 2013 (la séquelle d'unreal) le lead coder a libéré sur github le code de cette légende (https://github.com/mtuomi/SecondReality), et ce dernier est abondamment commenté depuis (http://fabiensanglard.net/second_reality/index.php par exemple).
En farfouillant le net, je me suis rendu compte qu'il n'existait rien sur leur "premiere" démo... Je me suis donc attaqué à ce monument de la scene...
La démo arrive sur un seul .exe de 2.400.825 bytes et etait distribuée dans un fichier zip de 1.337.312 bytes (https://files.scene.org/view/demos/groups/future_crew/demos/unreal11.zip), cela peut faire sourire aujourd'hui, mais à l'époque, c'était beaucoup, elle etait diffusée via des modem qui downloadaient à +/- 2 KB/s (oui 2 kilobytes par secondes) ce qui fait qu'il fallait près de 11 minutes pour télécharger cette démo (vous pouvez comparer votre vitesse de download avec le lien sur scene.org.
ce fichier .exe contient a démo, la musique ET les assets graphique.
Deep dive dans le fichier
En regardant le code de second reality et en lisant l'excélente review de fabien, je me suis dit que unreal devait avoir la même structure. j'ai donc jeté un oeil sur l'exe via un petit utilitaire 'unp.exe' (http://unp.bencastricum.nl/) juste pour voir... et bingo... le fichier executable n'est pas de 2 mb, mais plutot de 25kb il s'agit donc bien d'un loader, voir même d'un DIS (Demo Interrupt Server), comme dans le cas de Second Reality.
Dans Second Reality, les parties et assets ne sont décrit que dans une série d'offset hardcodé dans le loader (c'est ce que nous apprends le code source du loader de second reality) et actuellement, il m'est impossible d'obtenir les sources de "unreal.exe", donc en désepoir de cause, je jette un petit coup d'oeil sur le fichier en mode hexa; nous savons déjà que les 26315 (+le header DOS de 32 bytes) premiers octets contiennent le loader et sans doute également le DIS et sont donc sans intéret... les données (musiques, graphiques, etc) commencent après l'offset 26315+32, soit 26347, ou 0x66EB en hexa cette valeur va réapparaitre comme par miracle plus tard.
Tout en parcourant le fichier, j'ai vu des chaines de caractère, notament "Scream Tracker V3.0... (offset 0x1430), en parcourant tout le fichier, je suis arrivé à la fin du fichier,et une série de "noms" de fichiers sont apparus, j'en ai compté 97 en tout. On remarque ci-dessous que le fichier contient également des sous executables (sans doute les sous-parties de la démo).
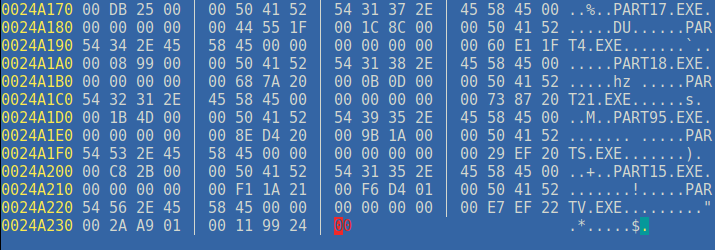
Il y a aussi une pattern très claire 16 octets pour le nom de fichier, et de 2 mots de 32 bits, soit un "bloc" de 24 octets au total que l'on peut décrire comme ceci:
{
char fname[16];
unsigned long offset;
unsigned long size;
} FileDef;
Toutefois, il y a un dernier "unsigned long" à la fin (0x00249911) qui est assez finalement assez simple à déduire; il s'agit d'un pointeur d'offset sur le début de la table de fichier:
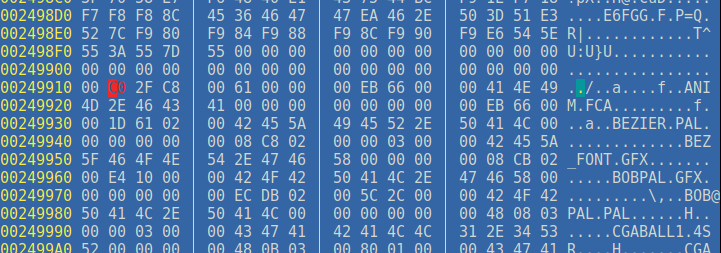
Sauf que à l'offset pointé, il y a 3 unsigned long:
- 0x00C82FC0 (13119424) aucune idée de ce que cela représente, un header ? un checksum ???
- 0x00000061 (97) : le nombre d'entrée dans le répertoire
- 0x000066EB (26347) : la fin taille total du loader (code + header DOS)
Sur base de ce que l'on vient de découvir, il est donc assez facile de lire le répertoire, et d'en extraire les parties.
#include <conio.h>
#include <malloc.h>
#include <string.h>
#include <dir.h>
typedef struct
{
char fname[16];
unsigned long offset;
unsigned long size;
} FC_FILE_ENTRY;
FILE *fc_blob;
FC_FILE_ENTRY *fc_directory;
unsigned long fc_directory_size;
void main()
{
unsigned long fsize=0, dirstart=0;
unsigned long header[3],i;
fc_blob = fopen(file,"rb"); // open file
if (!fc_blob)
{
puts("\nFile not found\n");
exit(1);
}
fseek(fc_blob,0,SEEK_END);
fsize = ftell(fc_blob); // get file size
fseek(fc_blob,fsize-4,SEEK_SET); // read directory pointer
fread(&dirstart,4,1,fc_blob);
fseek(fc_blob,dirstart,SEEK_SET); // read directory header (header, entry count, loader )
fread(&header,4,3,fc_blob);
fc_directory_size = header[1];
fc_directory = malloc(sizeof(FC_FILE_ENTRY)*fc_directory_size);
fread(fc_directory,sizeof(FC_FILE_ENTRY),fc_directory_size,fc_blob);
fclose(fc_blob);
for(i=0;i<fc_directory_size; i++)
{
printf("%16s %08lX %08lX\n",fc_directory[i].fname,fc_directory[i].offset,fc_directory[i].size);
}
}
Ce code devrait nous permettre de "voir" le répertoire dans la démo...
L'extraction des fichiers ne devrait poser AUCUN problème à ce niveau, il suffit de créer un fichier avec le nom fname, de se déplacé à l'offset spécifié dans le fichier source, et de copier size octets dans ce ficihier.
Prochaine étape, l'analyse des assets...
[TBC]
Références:
- Code source de Second Reality : https://github.com/mtuomi/SecondReality
- Code review par Fabien Sanglard : http://fabiensanglard.net/second_reality/index.php
downloadable:
- Référence de la démo : http://www.pouet.net/prod.php?which=1274
- La démo Unreal de future Crew : https://files.scene.org/view/demos/groups/future_crew/demos/unreal11.zip
- unp : http://unp.bencastricum.nl/
Tutoriaux: 3D - Théories et mathématiques
Introduction
Petite piqure de rappel, le calcul en 3 dimension n’est pas plus compliqué que le calcul en 2 (ou en 1) dimension, tous le monde est capable d'additionner et de multiplier des nombres...
Le calcul en 1 dimension est en fait le calcul d’algèbre classique, que vous faites tous les jours en faisant vos courses par exemple.
Le calcul en 2 dimension est de la géométrie simple, rappelez vous les translations, homotétites, rotations, (bon ce dernier point est souvent abordé en cours de trigonométrie), mais en réalité, le calcul 3D n’est jamais que l’extension des deux premiers espaces, ou si on est « positif », le calcul en 2 dimensions ou algébrique n’est jamais qu’une simplification du calcul en 3D.
Malheuresement, pour comprendre et "masteriser" la 3d sur ordinateur, un gros bloc de théorie mathématique est a lire, je vais essayer de le faire aussi court mais complet que possible...
Systeme de références
Tout est une question de références, il existes trois grands systemes pour décrire un espace en trois dimensions, il existe trois grands « système » de représentation mathématique.
Le systeme cartésien
Sans doute le plus simple a comprendre car le plus proche de notre mode « mathématique ».
Une coordonnée est exprimée « simplement » avec avec trois coordonnées : x, y, z
Radian vs Degré
Très souvent, dans les fonctions de trigonométriques informatiques, les angles sont exprimés en radian, et non en degrés (d'angle).
un radian est une valeur réel, alors qu'un degré d'angle est généralement un entier.
Notre cerveau a plus facile a manipuler la notion même de degré d'angle, car les valeurs nous sont plus communes : 0°, 90° pour un angle droit, 180°, etc...
pourtant, il est impératif d'utiliser des radians lorsqu'on fait des calculs trigonométriques, nous allons directement voir la relation entre radian et degré d'angle (180 degré d'angle, correspondent à Π radian)
Donc 1 radian vaut +/- 57.2958 degré d'angle (suivant la valeur de Π pour effectuer la conversion) pour connaitre la valeur (exacte) d'un radian, il suffit de:
Les formules de conversion sont donc les suivantes:
degré -> radian
radian -> degré
le systeme sphérique
C’est le systeme qui est utilisé pour la géolocalisation ou la définition d’objets céleste ; on parle de coordonnées angulaire (appelées latitude et longitude dans la géolocalisation) et d’un rayon (l’altitude pour ce qui est de la géolocalisaion, ou distance dans le cas d’objets céleste) :
Une coordonnée est exprimée avec un rayon r et deux angles : r, θ, φ.
le systeme cylindrique
Ce systeme est le moins répendu, et souvent utilisé pour pour l’étude de mouvements hélicoïdaux ou en rotation autour d’un axe.
Une coordonnée est exprimée via deux angles : ρ, φ, et une distance : z
Conversions entre systèmes de références
Sphérique → Cartésien
y = r * sin (θ) * cos (φ)
z = r * cos (θ)
Cylindrique → Cartésien
y = ρ sin( φ)
z = z
Calculs et matrices
En calcul 3D, le calcul matriciel la méthode la plus simple pour résoudre les transformations que l'on veut appliquer.
De plus, les opperations nécéssaires se limitent surtout à deux oppérations majeurs : la multiplication des matrices (produit matriciel) et l'addition de matrices.
Pour additionner 2 matrices, il sagit de faire la somme de leurs membres:
|a2 b2| + |c2 d2| = |(a2+c2) (b2+d2)|
Pour la multiplication, on utilisera la technique "LICOL" (Ligne Colonne), on multiplie chaque ligne par la colonne.
|a2 b2| * |c2 d2| = |(a2*c1)+(b2*c2) (a2*d1)+(b2*d2)|
Note sur la multiplication par 1
Dans un calcul simple, quand on multiplie n'importe quelle valeur par 1 on obtient toujours la valeur d'origine :
et donc x' = x
En calcul matriciel , la valeur '1' se présente comme ceci:
|0 1|
Pour des questions pratiques, je ne me pencherais que sur le systeme cartésien, plus lisible et surtout plus commun, mais sachez qu’il est tout a fait possible de convertir une carte de la galaxie (qui est trouvable en coordonnées sphérique) dans un systeme cartésien:
et, ainsi la multiplication d'une matrice par '1' se présente comme ceci :
|y'| = |y| * |0 1 0|
|z'| |z| |0 0 1|
Comme tous les langages de programmations n'incluent pas nativement le support de calcul matriciel, il convient de traduire ce produit matriciel en fonction simple (ou en une dimension) et de le faire pour chaque membre de la coordonnée que l'on veut calculer, vu la méthode LICOL que nous avons vu plus haut, cela devient donc:
y' = (x*0) + (y*1) + (z*0)
z' = (x*0) + (y*0) + (z*1)
Ce qui dans ce cas précis peut s'optimiser par l'application des formules suivantes:
y' = y * 1
z' = z * 1
Coordonnées homogènes
Toutefois, pour pouvoir correctement appliquer certaines transformations (notament la translation), dans certaines litératures, on rends homogènes les matrices, en ajoutant une 4ème valeur w, qui doit TOUJOURS être mise à 1, on parle alors de matrices homogènes :
|0 1 0 0|
|0 0 1 0|
|0 0 0 1|
Ce qui peut se traduire simplement :
y' = (x*0) + (y*1) + (z*0) + (w*0)
z' = (x*0) + (y*0) + (z*1) + (w*0)
w' = (x*0) + (y*0) + (z*0) + (w*1)
Ou encore en mode "optimisé", afin de démontré que les matrices, c'est simple :
y' = y * 1
z' = z * 1
w' = w * 1
En résumé, un produit matriciel d'une matrice point "P" avec une matrice de transformation "T" s'écrit comme ceci:
|y'| = |y| |ya yb yc yd|
|z'| = |z| * |za zb zc zd|
|w'| = |w| |wa wb wc wd|
Et se résouds avec les équations suivantes:
y' = (x*ya) + (y*yb) + (z*yb) + (w*yd)
z' = (x*za) + (y*zb) + (z*zb) + (w*zd)
w' = (w*wa) + (w*wb) + (w*wb) + (w*wd)
On constate immédiatement que l'ajout de la coordonnée "w" a dans cette serie d'équations peut influancé grandement (ou pas) les résultats.
Transformations
Tout ensemble de transformations géométrique doit se faire dans un certain ordre qu'il convient de décider à l'avance.
Une rotation suivit d'une translation et d'un changement d'échelle, dans cet ordre, ne donneront pas le même résultat qu'un changement d'échelle suivit d'une rotation et enfin de la translation...
Sans compter qu'il existe des transformations "plus fun" comme le scissaillement ou le mirroir suivant un plan...
Dans cette je ne fournirais que les matrices (et leurs traductions sans optimisation).
Les changement d'échelle
Sans doute la matrice la plus simple, la matrice de transformation d'échelle:
| 0 ey 0 0|
| 0 0 ez 0|
| 0 0 0 1|
On peut soit avoir une même echelle pour tout les axes : ex = ey = ez = echelle ou faire un changement d'échelle propre à chaque axes (ce qui peut amener des résultats rigolo).
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y*ey) + (z* 0) + (w* 0)
z' = (x* 0) + (y* 0) + (z*ez) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Translation
Si il existe une transformation souvent sous estimée, c'est bien celle-ci, le déplacement d'un point dans l'espace:
| 0 1 0 0|
| 0 0 1 0|
|tx ty tz 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y* 1) + (z* 0) + (w*ty)
z' = (x* 0) + (y* 0) + (z* 1) + (w*tz)
w' = (x*tx) + (y*ty) + (z*tz) + (w* 1)
Rappelez vous que w = 1, et donc nos formules peuvent se traduire par:
y' = y+ty
z' = z+tz
Réflection par rapport à un axe
Avec cette transformation, il est facile d'avoir le mirroir d'un point par rapport à un des axes, cela peut servir soit pour créer un double de l'objet, soit pour le représenter "en mode mirroir"... (a vous de voir si vous dupliquez ou non le point)
Le plan de "mirroir" est toujours défini par rapport a deux axes:
Effet mirroir par rapport au plan x/y (chaque coordonnée 'z' sera inversée):
| 0 1 0 0|
| 0 0 -1 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y* 1) + (z* 0) + (w* 0)
z' = (x* 0) * (y* 0) * (z*-1) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Effet mirroir par rapport au plan x/z (chaque coordonnée 'y' sera inversée):
| 0 -1 0 0|
| 0 0 1 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y*-1) + (z* 0) + (w* 0)
z' = (x* 0) * (y* 0) * (z* 1) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Effet mirroir par rapport au plan y/z (chaque coordonnée 'x' sera inversée):
| 0 1 0 0|
| 0 0 1 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y* 1) + (z* 0) + (w* 0)
z' = (x* 0) * (y* 0) * (z* 1) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Rotation autour des axes de références
C'est dans les rotations que les choses se compliquent, et que la trigonométrie commence, c'est aussi dans les rotations que l'on prends vraiment la troisième dimension "dans les yeux"; Nous allons différencier les 3 axes, mais en réalité les matrices sont particulièrement similaires...
Autour de l'axe Y, avec un angle de ay °
| 0 1 0 0|
| sin(ay) 0 cos(ay) 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y* 1) + (z* 0) + (w* 0)
z' = (x* sin(ay)) + (y* 0) + (z* cos(ay)) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Autour de l'axe X, avec un angle de ax °
| 0 cos(ax) sin(ax) 0|
| 0 -sin(ax) cos(ax) 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x* 0) + (y* 1) + (z* 0) + (w* 0)
z' = (x* sin(ax)) + (y* 0) + (z* cos(ay)) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Autour de l'axe Z, avec un angle de az °
|-sin(az) cos(az) 0 0|
| 0 0 1 0|
| 0 0 0 1|
Voici les formules a appliquer si l'on désire transformer un point particulier:
y' = (x*-sin(az)) + (y* cos(az)) + (z* 0) + (w* 0)
z' = (x* 0) + (y* 0) + (z* 1) + (w* 0)
w' = (x* 0) + (y* 0) + (z* 0) + (w* 1)
Conclusions temporaires
Avec ces outils, il est possible de modifier un point (ou des points) dans l'espace, et de le(s) placer avec précision où l'on veut (on peut aussi appliquer une transformation puis une autre dans n'importe quel ordre), et créer a chaque fois un nouveau point...
Ces transformations modifient la positions des points dans l'univers; nous y reviendrons plus tard...
Il est important de noter que ces transformations sont des outils aidant à créer d'autre points, ainsi si l'on dessine une forme (avec des points) sur un plan X/Y, il est très facile de dupliquer ces points en faisant 36 rotations de 10° à chaque fois, et ainsi de créer un objet en 3D "tourné" a partir d'un simple profile.
Dans la suite de cet article, je resterais (sauf exception) sur des matrices "classiques" à 3 valeurs (x,y,z).
Projection sur l'écran
Il nous reste à aborder le passage de la 3D à la 2D (pour nos "simple" écrans)...
Nous avons transformé des points (qui peuvent former des objets) dans un espace à 3 dimensions, avec un point remarquable (0,0,0) qui est le centre de l'univers cartésiens ainsi décrit.
Par défaut, si l'on applique les formules de projection ci-dessous, l'observateur sera un point "remarquable" (et immobile) situé en (0,0,0) et rqui egarderarait vers le fond (0°,0°,0°) ... :D
Projection sans distance, projection orthonormée (projection du fénéant)
Si l'on désire représenter un point 3D en 2D, après transformation(s), on peut simplement ignorer la coordonnées 'Z'
y' = y
Centrer l'écran
Sachant qu'un écran informatique peut afficher des points de 0,0 à sizex, sizey et que les valeurs de x' et y' peuvent quand à elles varier t entre -∞ et +∞, il convient de centrer le 0,0 sur l'écran et d'éliminer les valeurs "hors écran"
y' = y' - (sizey/2)
if ((x'>=0) and (x'<sizex) and (y'>=0) and (y<sizey))
draw_pixel(x',y',1)
Projection Simple dit aussi Projection du pauvre
Si l'on désire représenter un point 3D en 2D, après transformation(s), on simuler l'éloignement (par rapport à l'observateur) en faisant un rapport sur la valeur z, après transformation:
y' = y / z
Cette projection transforme un point 3D en 2D en tenant compte de l'éloignement, plus le Z est grand, plus les points projetés se "rapprochent" les un des autres autour du 0,0, et donc donneront l'ilusion d'etre "plus loin".
C'est la technique qui est utilisée en peinture (technique du "point de fuite") pour donner un sentiment de "profondeur" à l'image, on parle alors de perspective.
Dans cette projection, Il convient toutefois de prendre en compte le risque d'avoir un z nulle avant d'appliquer la projection.
Cas du 'Z' nulle
On peut soit ignorer les points qui sont sur l'origine, soit les afficher en utilisant la projection du fénéant, je conseille de quand meme les afficher.
{
x' = x
y' = y
}
else
{
x' = x / z
y' = y / z
}
Cette gestion ne vous empeches pas de quand meme centrer votre 0,0 et les "hors-écran", donc alourdis un peu la projection.
Projection sur l'écran
Considérons un instant l'écran (de projection) comme pouvant se situé entre l'observateur et l'objet observé, il convient de prendre en compte cette différence, afin notament de gérer l'effet de focale (et éventuellement de traiter le centrage)...
la projection sera dès lors calculée avec les formules suivantes
y' = y*(ez/z) + ey
Si l'on considère que ex = -(sizex/2) et ey = -(sizey/2), et que ez=1, alors nous retombons sur la formule de la projection du pauvre... qui tiens nativement compte du centrage de l'écran...
Caméra et point de vue
Dans les projections précédentes, nous avons toujours fait bouger les points de l'univers autours du 0,0,0 et non fait bouger un observateur dans cet univers, la logique voudrait que ce soit en effet l'observateur qui se déplace et non l'univers.
Si l'on désire faire entrer la notion d'observateur(caméra)/point de vue, il convient d'inclure ce point (et là ou il regarde) dans les calculs de transformation/projection et d'appliquer aux points de l'univers une transformation spéciale.
Si l'on désire appliquer les transformations en prenant en compte la position de l'observateur, il convient d'appliquer la transformation de la caméra, cette transformation inclu une rotation autour de l'axe Z, de l'axe Y et de l'axe X de chaque point par rapport à la position de l'observateur/caméra et à son orientation (du regard).
Soit:
ox,oy,oz : coordonnées cartésienne, position de l'oeil dans l'espace.
ax,ay,az : angles de vue , ces angles définissent la direction du regard à partir du point de l'observateur (ox,oy,oz).
Alors la matrice de transformation devient
|y'| = | 0 cos(ax) sin(ax)| * | 0 1| * |-sin(az) cos(az) 0| * (|y| - |oy|)
|z'| | 0 -sin(ax) cos(ax)| | sin(ay) 0 cos(ay)| | 0 0 1| |z| |oz|
Note:
Dans l'introduction à la projection, j'ai évoqué l'observateur comme étant un point remarquable du système localisé en (0,0,0), et ayant une direction de regard a angle nul (0°,0°,0°)
Si l'on n'a pas d'angle de vue (ax=ay=az=0), les matrices de rotation deviennent des matrices "unités" (car (sin(0)=0 et cos(0)=1), et l'on peut dès lors simplifier le produit en "translation"
|y'| = |y| - |oy|
|z'| |z| |oz|
Mais il ne faut pas oublié que l'observateur est le 0,0,0; ce qui veut dire que ox=oy=oz=0, alors
|y'| = |y|
|z'| |z|
Et l'on retombe bien sur une matrice toute simple.
Conclusions
Il est impossible de conclure simplement, mais je vais tenter de résumer au mieux tout ce qui a été vu, et de fournir une matrice/formule simple
vec quelques définitions voici les formules que nous allons implémenter.
soit:
x[],y[],z[] : coordonnées cartésienne des points a transformer
ex,ey,ez : coordonnées cartésienne de l'écran
avec ex=-(sizex/2), ey=-(sizey/2) et ez=1
ax,ay,az : angles de vue , ces angles définissent la direction du regard à partir du point de l'observateur (ox,oy,oz).
cx = cos(ax), sx = sin(ax), cy = cos(ay), ...
nx,ny,,nz : coordonnées cartésienne, position temporaire de calcul
pseudo code:
{
dx = x[]-ox
dy = y[]-oy
dz = z[]-oz
nx = cy*(sz*dy + cz*dx) - sy*dz
ny = sx*(cy*dz + sy*(sz*dy + cz*dx)) + cx*(cz*dy - sz*dx)
nz = cx*(cy*dz + sy*(sz*dy + cz*dx)) - sx*(cz*dy - sz*dx)
x' = nx*(ez/nz) + ex
y' = ny*(ez/nz) + ey
}
Références
3D et vrai Relief
J.J.Meyer
ISBN: 2-7091-0990-5
https://www.amazon.co.uk/3D-vrai-relief-images-synthese/dp/2709109905
PC Interdit 2eme édition Windows 95 & Jeux 3D
Boris Bertelsons, Mathias Rasch et Jan Erik Hoffmann
ISBN: 2-7429-0500-6
https://www.amazon.fr/PC-interdit-Collectif/dp/2742905006
Mathematics of 3D Graphics
Juan David Gonzalez Cobas
Universidad de Oviedo
Blender Conference 2004
https://www.cs.trinity.edu/~jhowland/class.files.cs357.html/blender/blender-stuff/m3d.pdf
http://www.ecere.com/3dbhole/mathematics_of_3d_graphics.html
https://en.wikipedia.org/wiki/3D_projection
https://fr.wikipedia.org/wiki/Projection_(g%C3%A9om%C3%A9trie)
https://fr.wikipedia.org/wiki/Perspective_axonom%C3%A9trique
Compare Intel 80486 vs Motorola 68040 - Advanced Microprocessors
System Comparison
Most of the space in this text is dedicated to the most recent advanced CISC microprocessors, the top current products within their families; the Intel 80486 and the Motorola MC68040.
They both belong to the latest 1.2 million transistors per chip generation. It therefore makes sense to compare the two.
It would be unfair to compare the NS32532 with them, since the NS32532 belongs to an earlier generation and it is not in the same class as the 80486 and MC68040.
A selection of points of comparison between the 80486 and the MC68040 is listed in Table 1.1.
Looking carefully at the table, one can perceive only a single line indentically marked in both columns: both chips have an on-chip FPU, conforming to the IEEE 754-1985 standard.
All other data are different, although quite close in some instances. The points of difference between the 80486 and the MC68040 will be discussed next in some detail.
-------------------------------------------------------------------------------
Feature Intel 80486 Motorola MC68040
-------------------------------------------------------------------------------
FPU on Chip Yes (IEEE) Yes (IEEE)
CPU General-Purpose 32-bit Registers 8 16; 8 Data/8 Address
FPU 80-bit Registers 8 (stack) 8
MMU on Chip Yes Yes; Dual: Data, Code
Cache on Chip 8k Mixed 4k Data + 4k Code
Segmentation Yes No
Paging Yes; 4k/page Yes; 4k or 8k/page
TLB (or ATC) size 32 entries 64 entries in each: Data, Code ATC
Levels of protection 4 2
Instruction pipeline stages 5 6
Pins 168 179
-------------------------------------------------------------------------------
CPU General-Purpose Registers
Both systems have 32-bit general-purpose registers; the 80486 has 8, while the 68040 has double that number, namely 16. There are advantages (and disadvantages) to having a large register file.
The register file of the 80486 is definitely too small to avail itself to the advantages. This is particularly exacerbated by the fact that the CPU registers of the 80486 are not really quite as general purpose as one might wish.In fact, all of them are dedicated to certain special tasks, such as:
EDX Dedicated to some I/O operations
EBX, EBP Dedicated to serve as base registers for some addressing modes
ECX Dedicated to serve as a counter in LOOP instructions
ESP Dedicated to serve as a stack pointer
ESI, EDI Dedicated to serve as pointers in string instructions and as index registers in some addressing modes
On the other hand, on the MC68040 the eight 32-bit data registers D0 to D7 are genuinely general purpose without any restrictions or specific tasks imposed on them.
Of the eight 32-bit address registers A0 to A7, only A7 is dedicated as a stack pointer.
The user is free to use the other seven resgisters A0 to A6 in any possible way.
From the point of view of the CPU register file, the MC68040 has a very clear advantage.
It is much better equipped to retain intermediate results during a program run, thus reducing CPU-memory traffic.
From this standpoint, the MC68040 even has a slight edge over the VAX architecture.
The VAX (any VAX model) also has sixteen 32-bit general-purpose registers.
However, only 12 of those (as opposed to the 68040's 15) can be used freely by the programmer.
Of the four VAX dedicated registers, one is used as a program counter and another as a stack pointer.
The program counter is completely separate on both the MC68040 and the 80486 and is not included in the general-purpose registers.
FPU General-Purpose Registers
Both systems have eight 80-bit registers, providing a large range for floating-point number representation and a high level of precision.
The only differnce between the two is that the 80486 FPU registers are organized as a stack, while those of the MC68040 are accessed directly, as its integer CPU registers.
Because of the stack organization the 80486 might have a slight edge from the standpoint of compiler generation (for that part of the compiler dealing with floating-point operations).
MMU on Chip
The 80486 has a regular MMU on chip for the control and management of its memory.
The MC68040 has two MMUs: one for code and one for data.
This duality, supported by a separate operand data bus, allows the control unit to handle instruction and operand fetching simultaneously in parallel and enhances the handling of the instruction pipeline.
Of course, the external bus leading to the off-chip main memory is single (32-bit data, 32-bit address), and it is shared by instructions and data operands.
With a reasonable on-chip cache hit ratio, the off-chip bus would be used less often.
Cache on Chip
The total on-chip cache of both systems is 8 kbytes.
Interestingly enough, they have the same parameters: both are four-way set-associative with 16 bytes per line.
The difference is that while the 80486 on-chip 8k cache is mixed, storing both code and data the MC68040 cache is subdivided into two equal parts: a 4-kbyte data cache and a 4-kbyte code cache.
Each cache is controlled by the respective MMU, mentioned above.
The advantage, as in the MMU case, is the provision of two parallel paths for code and data, resulting in an overall speedup of operation.
Segmentation
The Intel 80x86 family implements segmentation, while the M68000 family does not.
The earlier Intel systems (8086, 80286) were plagued with the upper 64-kbyte segment size limit, starting with the 80386 and so on, the segment sizecan be made as high as 4 Gbytes (maximum size of the physical memory), effectively removing the segmentation feature by the decision of the user.
Therefore, as far as segmentation is concerned, the 80486 and MC68040 are comparable.
The 80486 has some edge, since it allows the user to implement segmentation if needed and avail oneself to its advantages.
Paging
The MMUs of both systems feature paged virtual memory management.
The 80486 offers a single standard page size of 4 kbytes.
This page size is implemented in many other systems.
With a 4-kbyte page size, one can arrange an address mapping where the page directory and the page tables also have the standard page size of 4 kbytes (1024 = 2^10 entries, 4 bytes each).
Thus, the page directory and the page tables can be treated as entire pages and placed within page frames in the memory.
This results in reduced complexity in the MMU hardware and in the OS software, one of whose tasks is to support the management of virtual memory.
The MC68040 offers two page sizes, selectable by the user: 4 kbytes and 8 kbytes.
This tends to complicate the MMU logic and the OS.
It is a good thing that Motorola got rid of the other page size options available with its MC68851 paged MMU: 8 sizes ranging from 256 bytes to 32 kbytes, stepped by a factor of 2.
On the other hand, the 8-kbyte per page option could be useful to a programmer dealing with large modules of code exceeding 4 kbytes.
TLB (or ATC) Size
The 80486 MMU has a 32-entry TLB.
With a 4-kbyte page it covers 32 x 4 kbytes = 128 kbytes of memory.
The MC68040 offers much more.
The TLB is called address translation cache (ATC) by Motorola, but it does the same: it translates virtual into physical addresses.
The name given by Motorola is simpler to perceive, although the TLB term is predominately used in the computer literature.
Each of the two MC68040 MMUs has a 64-entry ATC, for a total of 128 entries on the chip.
For a 4-kbyte page, a total of 128 x 4 kbytes = 512 kbytes of memory is covered (4 times that of the 80486), and for an 8-kbyte page, 1 Mbyte (8 times that of 80486).
In this case, a strong advantage of the MC68040 is obvious.
Since the ATCs encompass much more memory, the ATC miss probability is considerably smaller.
Thus, less time will be wasted in accessing page tables in memory, resulting in faster overall operation.
Levels of Protection
The 80486 offers four levels of protection, while the MC68040 has only two - the supervisor and user, as does the whole M68000 family.
While the protection mechanism of the 80486 is much more sophisticated and, with the segmentation encapsulation of information, offers more reliable protection, it also results in more complicated on-chip logic.
More time is taken up with protection checks on the 80486.
Instruction Pipeline Stages
The 80486 instruction pipeline has five stages, while that of the MC68040 has six.
This means that the 80486 pipeline can handle five instructions simultaneously and the MC68040 can handle six.
This certainly gives an edge in favor of the MC68040, although its MMU-cache-internal buses duality is a much stronger contributor to its enhanced speed of operation.
The above comments are valid if the instructions are executed sequentially, without any taken branches.
In the case of the taken branch, the subsequent prefetched instructions are flushed from the pipeline hardware.
Neither the 80486 nor the MC68040 employ the delayed branch feature, as do most of the RISC-type systems.
The MC68040 designers have investigated the possibilityof featuring a delayed branch or other techniques to alleviate the problem of lost cycles in case of a flushed pipeline.
After a number of simulations, they came to the conclusion that the gain in performance was not worth the extra hardware expenditure incurred in the implementation of any of the methods considered.
In RISC-type systems, on the other hand, due to reduced control circuitry there is extra space for features such as the delayed branch which alleviates the pipeline management problem in case of a taken branch.
Indeed, Intel's RISC 80860 and Motorola's RISC M88000 both implement the delayed branch technique as an option, selectable by the user.
Performance Benchmarks
-----------------------------------------------------------------------------
System Results - Kdhrystones/s Relative
-----------------------------------------------------------------------------
VAX 11/780 1.6 1.0
Motorola MC68030 (50 Mhz,1ws) 20.0 12.5
Intel 80486 (25 Mhz) 24.0 15.0
SPARC (25 Mhz) 27.0 16.8
Motorola M88000 (20 Mhz) 33.3 20.1
MIPS M/2000, R3000 (25 Mhz) 39.4 23.8
Motorola MC68040 (25 Mhz) 40.0 24.3
Intel 80860 (33.3 Mhz) 67.3 40.6
-----------------------------------------------------------------------------
As one can see, the MC68040 Dhrystone integer performance considerably exceeds that of the 80486.
It should also be noted that the MC68040 outperforms its predecessor MC68030 by a factor of 2, while the MC68030 operates at a double frequency.
-----------------------------------------------------------------------------
System Results - MFLOPS
-----------------------------------------------------------------------------
VAX 11/780 0.14
NS32532 + NS32381 0.17
Intel 80386 + 80387 (20 Mhz) 0.20
VAX 8600 0.49
Intel 80486 (25 Mhz) 1.0
Motorola M88000 (20 Mhz) 1.2
Sun SPARCstation 1 1.3
Decstation 3100 (MIPS R2000) 1.6
Sun 4/200 (SPARC) 1.6
Am29000 (25 Mhz) 1.71
IBM 3081 2.1
Motorola MC68040 (25 Mhz) 3.0
R3000/R3010 (25 Mhz) 3.9
Intel 80860 4.5
RS/6000 (25 Mhz) 10.9
Cray 1S 12.0
Cray X-MP 56.0
-----------------------------------------------------------------------------
Here, the MC68040 outperforms the 80486 by a factor of 3.
This performance ratio is well supported by the discussion given for the data in Table 1.1.
The fact that more RISC-type processors, tested above, outperform the 80486 CISC should not escape notice either.
This is particularly significant for floating-point performance where the 80486 has an on-chip FPU, while the R3000 and the SPARC use off-chip coprocessors.
A comparison of memory access clock cycles needed for the execution of ADD instructions is reported in the following:
-----------------------------------------------------------------------------
Source Destination MC68040 80486 M88000
-----------------------------------------------------------------------------
ADD reg reg 1 1 1
ADD mem reg (cache hit) 1 2 3*
ADD reg mem (cache hit) 1 1 3*
ADD mem reg (cache miss) 3 4 15*
-----------------------------------------------------------------------------
--"reg" represents a CPU register and "mem" represents a location in memory.
*Includes time to load register plus one clock for the ADD operation.
The superior performance of the MC68040 fits the discussion given earlier in this text.
It should also be noted that both the MC68040 and 80486 have an on-chip cache, while the M88000 cache is on a separate CMMU chip (MC88200).
It should be noted that all of the above comparisons were conducted with artificial benchmark programs such as Dhrystone.
It is quite possible that for some "real-life" programs the performance ordering might be quite different.
It is no accident that when company A conducts benchmark experiments, its products come out ahead of others.
It is quite possible that when another company, say B, publishes its own benchmark results, the performance ordering may look different.
Therefore, the sample of benchmark comparison results presented should be regarded as a tentative indication.
Source :Advanced Microprocessors by Daniel Tabak
scribed by : Mike - July 1992